Hi Everyone,
I need to provide figures on the rate of change for our backup data, as we are looking to send data to another location with two weeks retention.
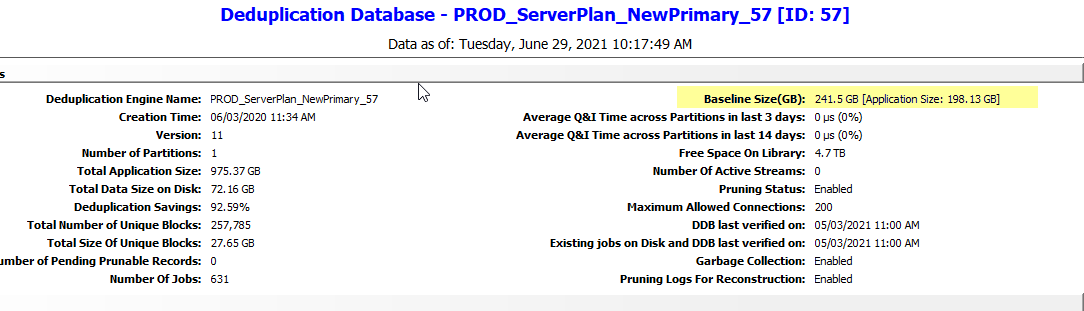
I have a mature, deduplicated environment so the figures I am seeing on reports and the like, are not too much use at the moment.
I need to really factor in two things:-
1 - Expected size of the baseline (I will be created a new copy, targeting the new location)
2 - The rate of change of future backups.
So I have two main questions:-
1 - How do I calculate my expected dedupe and compression savings for my first Auxcopy.
I realize this will effectively be copying over an equivalent full backup, since it will be seeding the new library.
I am thinking along the lines of assuming a 50% saving (compression and some dedupe combined) but I am wondering if there a better or more accurate way of doing this? My data is largely filesystem, so OS and server, but I may need to look at application data too (SQL\ Oracle).
2 - How do I calculate my future rate of change?
This should be much easier, but I am reading articles from people saying they use 6 or 7 incrementals and average them out.
However, if I’m keeping two weeks worth of data, then should I also not be including the figures from a full backup? At the moment, I am seeing figures like 15TB written, from an Application Size of 200TB on ALL backups over a seven day period.
So that is a pretty good return on savings, but how do I align this to future needs?
if you have experience of this, it would be good to hear from you.
Thanks
Best answer by Mike Z-man
View original