In practice we see many of our customers determining RTO’s based on paper exercises before even validating what it takes to live up to the RTO SLA agreement. In case organization refer to RTO-0 than they refer to high availability which can be achieved using for example clustering technologies combined with sync. mirror storage or application with built-in capabilities relying in a distributed backend. However it doesn’t protect in case you run into cyber security threats, malicious intent or human failure.
Now you have to rely on your backup copy to recovery to a specific point in time. Now let’s forget the time that it takes before the actual recovery process starts which is easily forgotten, but what actually adds-up to the entire recovery time. Let’s not take into account the MTD which stand for the maximum tolerated downtime as well but let’s focus on the RTO definition within Commvault. What is the rule of thumb that Commvault uses itself to determine the RTO? I remember to recall the rule of thumb full backup duration + 20%, but is that still correct? I of course do not take into account snapshot possibilities, but really focus on the RTO related to a full recovery from a backup copy.
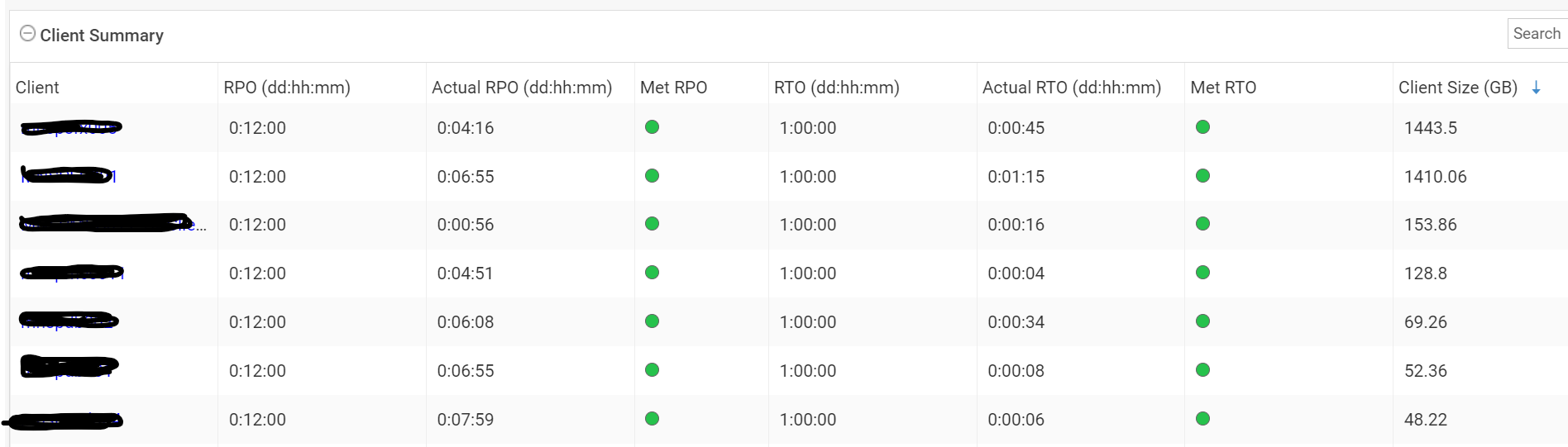
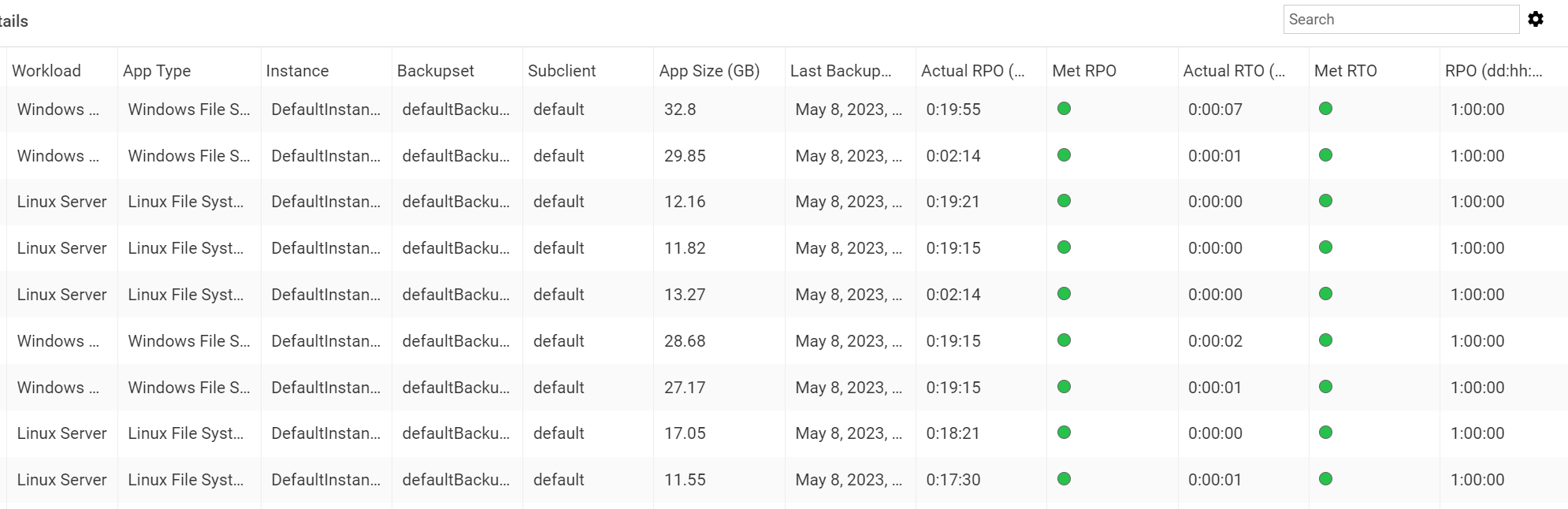
I had a look at the readiness report and although the report looks nice, the calculated RTOs just doesn’t seem to be realistic. B.t.w. the latest report ran on a CommCell running the latest FR30 maintenance release.
Curious to hear if others noticed the same, to learn from your experiences and I would also like to get confirmation if the rule of thumb is correct.