


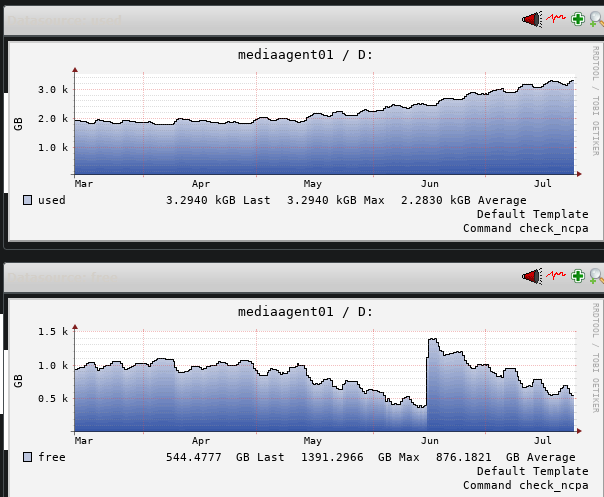
I have a RAID-6 array of SSDs, 3.5TB in size, on my main mediaagent, that is configured as a single volume that contains both the index folder, and the DDB. For the past 4 months, we’ve seen an explosion of growth on this volume, almost doubling. My linux file server admin believes that one of our customer’s research projects is creating millions of small files, editing them over a few days, then deleting them; i.e. inode growth and free space is about the same, but of course commvault is needing to track and retain this information in each incremental backup.
We added another SSD to the array in early June to hold off the array getting full, but as you can see, the massive growth continues.
Our backup retention strategy is 3x incremental backups every day, Sunday through Friday, and Saturday is used exclusively to create a synth full of the weekly incrementals. At the end of each month, the last saturday’s synth full is retained, and all other incrementals and synth fulls are aged out. We keep every client’s last 12 synth fulls - i.e. one year of backups with granularity of one month.
Index retention on MediaAgent01 was 15 days; I changed it down to 10 days about a week ago to see if it would make a difference. I already figured it would not though, as long as whatever file creation/editing/deletion behavior is occurring continues.
To confirm this theory, is there a report or method I can use to see which clients/subclients are causing the most growth in the Index?
Best answer by Damian Andre
View original




