Hey everyone,
I’ve got a bit of a puzzler. We have several years of data on prem, and in a 3rd party S3 bucket. We’re looking to reduce the footprint of this on prem and 3rd party S3 bucket somewhat, and are moving the data to AWS and Azure combined storage tier libraries as it’s long term data that we need to keep per SLA, but do not expect to recover from unless a project is resurrected or a legal search request comes in, and as such, we can lower some costs by storing it on the lower cost AWS and Azure offerings.
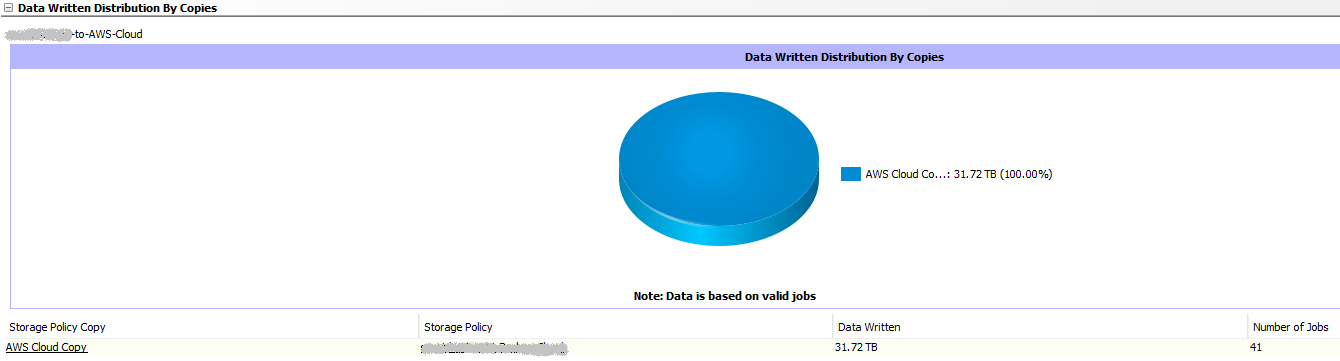
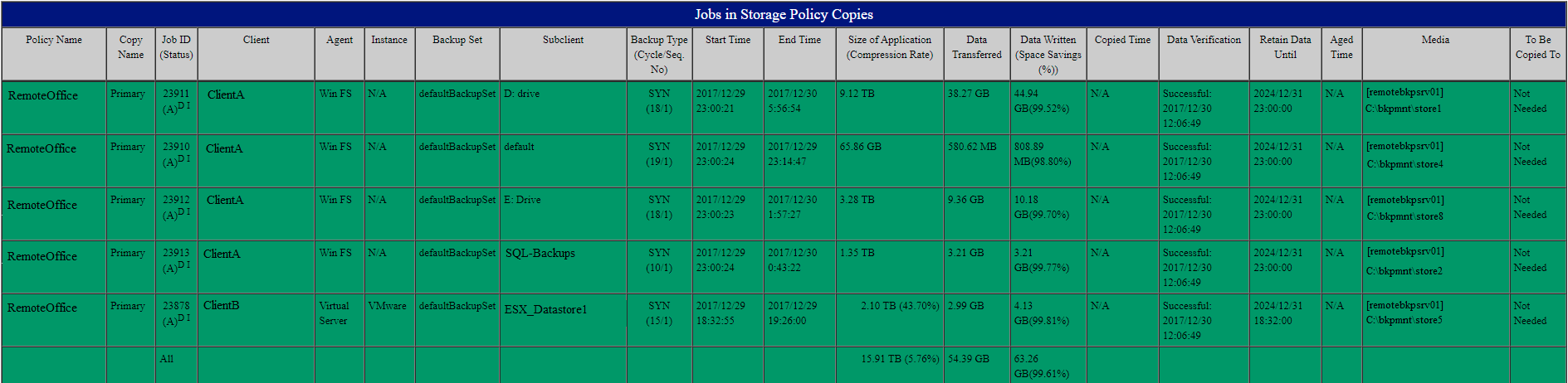
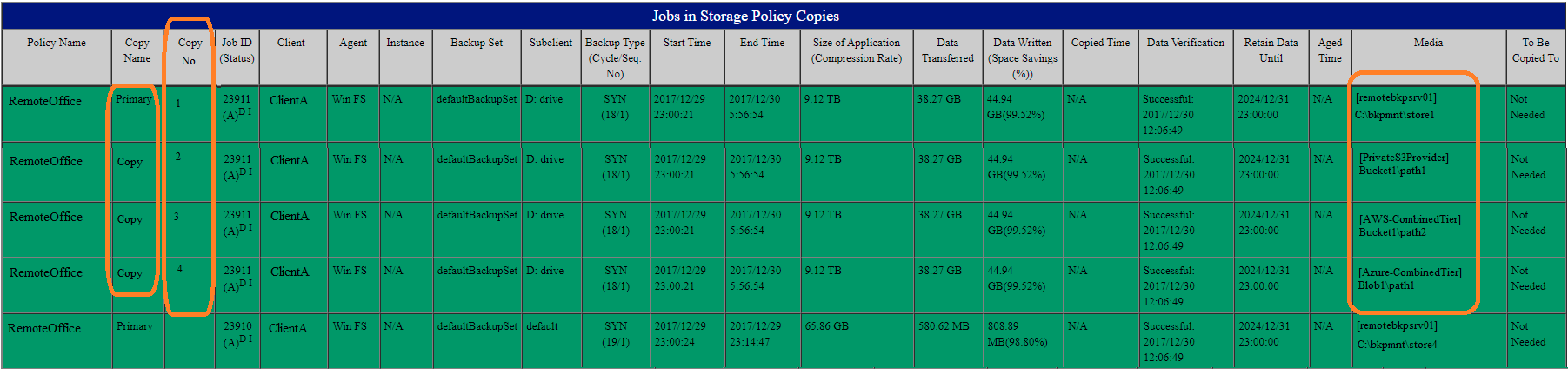
The test Aux copies worked quite well - I can see that both my AWS and Azure libraries have the same number of jobs, and the same total data, but if I am asked by an auditor to show that during this work, for client X, that data was on prem, at the 3rd party S3 site, and at AWS and Azure, before I clear it from on prem and the 3rd party S3, I have no idea how to get a report showing that there are 4 copies of the data. Alternately, an Auditor could say show me for job XXXX where data resided on this date, and where it resides today.
By the same token, I’ve no easy way/understanding of how to determine the differences in the on prem library vs the 3rd party S3, and there are some that I will need to account for.
In my days of working with NetBackup, I could run commands to show that we had copy 1, 2, 3, and 4, and where those copies were (be it tape or disk). Unfortunately, the same number of jobs, and same TB size being shown for two libraries does not actually mean it’s the same data, not scientifically anyway. ![]()
Ultimately, I want to have a record showing the data exists before I start to prune, and I want this stored outside of CV as a point in time record showing the chain of custody if you will as we revamp our storage policies.
I’ve tried to play with the custom report tools but I’ve only been playing with CV for about a year or so now, and frankly, I don’t understand the DB schema to figure out what tables I need to pull together to extract the data - I also know I’m a lousy DBA - and most databases will misbehave for me (it goes all the way back to my post secondary years).
To date, none of the reports I’ve looked at get even remotely near what I want, and I can’t do this via the GUI for each and every client and VM we have by doing a browse and restore type operation - there’s just too many systems.
Is there a way to get there from here? ![]()
Thanks!
Best answer by D. Kerrivan
View original