


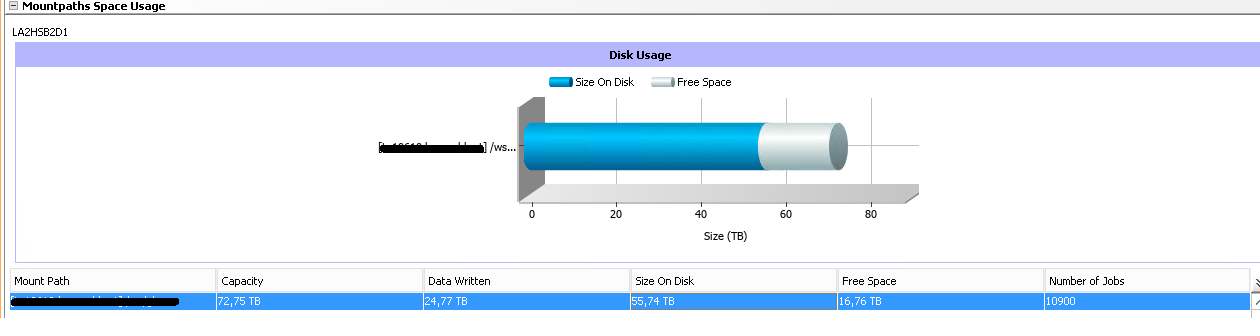
Size on disk 55,74 TB, but data written is 24,77 TB
Hi folks,
I’m trying to figure this out for few hours and I still didn’t find anything wrong in the Storage Policy, DiskLib, Media Agent properties... Backup jobs are also fine. I have counted 10800 jobs manually, just to be sure that the size is correct. 24,77 TB of data is written. BUT how it can be possible, that size on disk takes 55,74 TB?
Did someone had the same situation?
Best answer by gjack
View original





