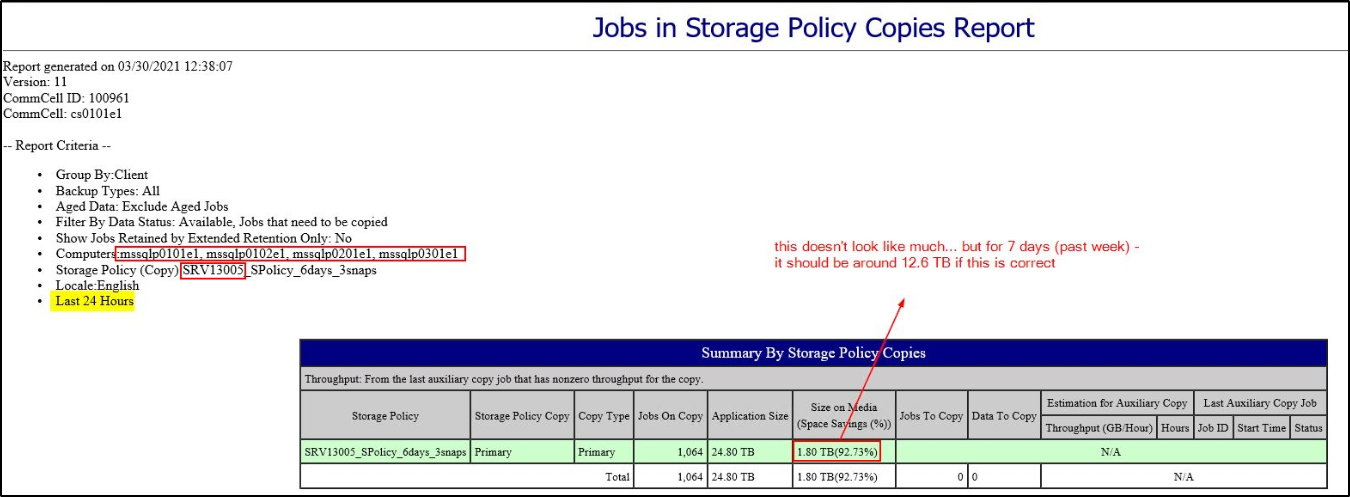
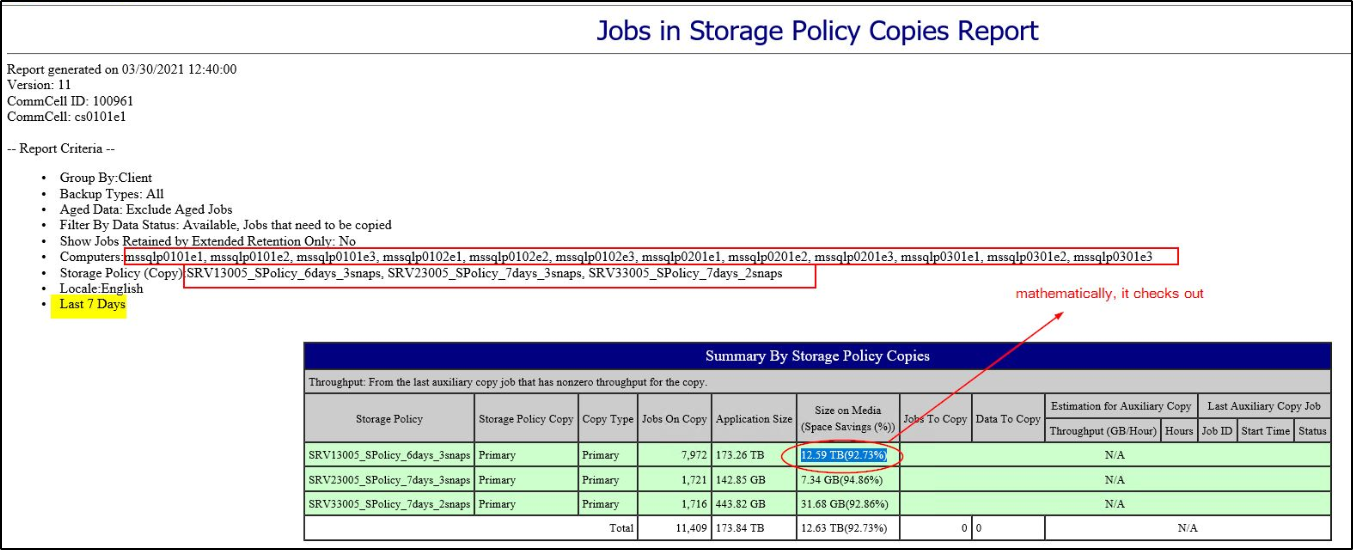
Hello all,
I ran into a bit of an issue… Yesterday, one of the Disk Libraries got filled up and the backups went into waiting status. After haveing a look at the utilization, indeed it turned out to be 99,7% full.
The main culprit were SQL server backups:
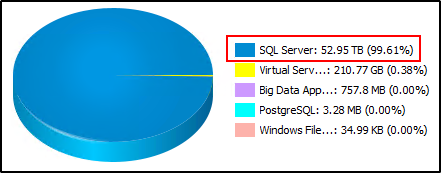
There were some backup jobs with an extended retention - so I’ve deleted those, and some more of the old backup jobs to make space. I also ran Data Aging and could clearly see data chunks being deleted in SIDBPhysicalDeletes.log and after a while I got this:
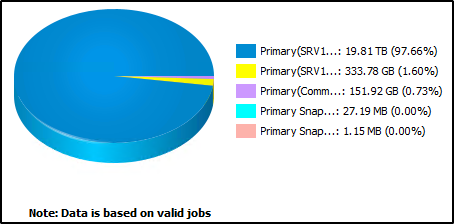
So, I assume quite a bit of data was deleted. The Primary copy (blue) went from 52.95TB down to 19.81 TB.
However, when I check the Free Space on the Library I got very little:

So I checked the Mountpaths Space Usage for that DL:
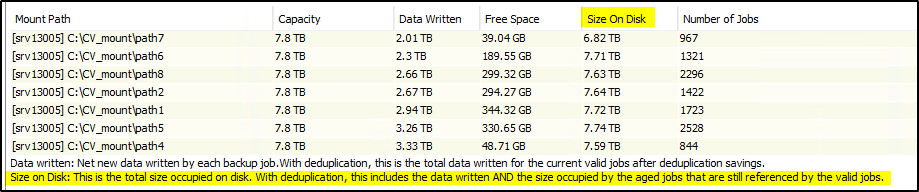
Data Written corresponds to amount of space used by the Primary copy: 19.8 TB
However Size on Disk, which takes into account Data Written + aged jobs which are still referenced by valid jobs is still very high. Almost unchanged.
I am quite confused by this. It seems that the data got aged (deleted) but it’s still being referenced and therefore… not deleted?
I've performed:
- Storage Resources → Storage Policy Copy → Databases → Run Data Verification
- Storage Resources → Storage Policy Copy → Databases → Validate And Pruned Aged Data (successfully validated and resync-ed)
Nothing’s changed.
How can I reduce Size on Disk? Is there a way to force a physical purge of aged referenced jobs so that I can finally free up some space?
I am out of ideas and need to figure this out quickly, so any help would be appreciated. Thanks in advance!
Regards,
Igor