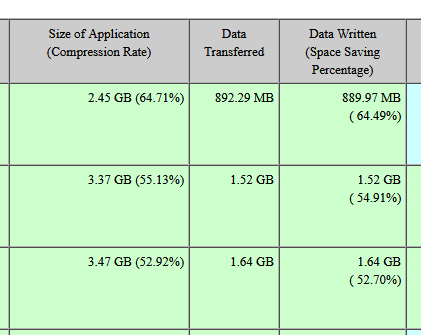
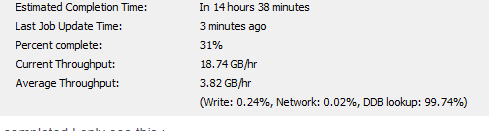
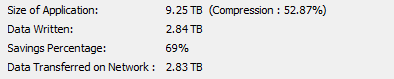
How do I read this job status data? What is my deduplication savings if any, or is it just compression alone. Where do I look for actual deduplication savings for the job.
Can I leave deduplication enabled for transaction logs, or will that affect performance?
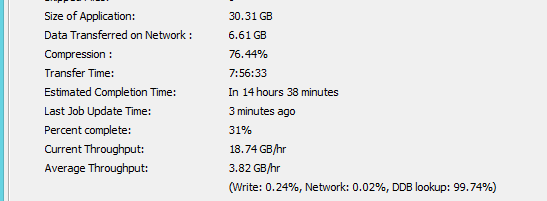
Once job is completed I only see this :
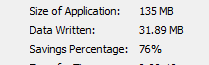
Could it be that
my dedupe savings is nil? Or am I am mixing the terms and compression is actually a deduplication?
Best answer by Damian Andre
View original