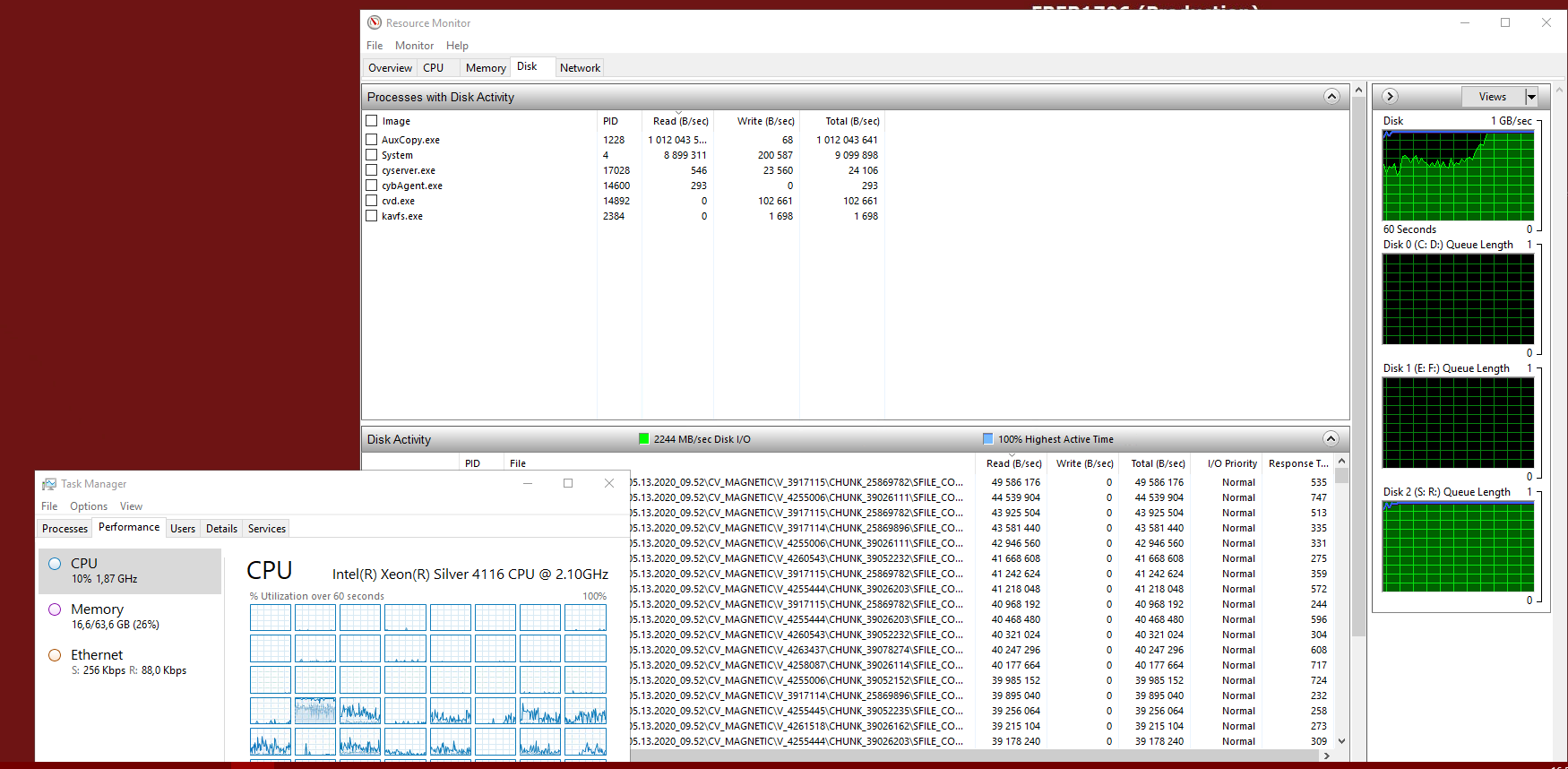
Our Media Agent needs replacing.
The replacement is probably going to be a Dell PowerEdge R5xx or R7xx with dual CPU and 128GB RAM and the intention is to use M.2/NVMe for the OS/Commvault binaries and DDB/Indexes but I’d appreciate any guidance and best practise on the build and storage.
We’re doing a lot of synthetic fulls with small nightly incremental backups and we aux about 70TB to LTO8 tape every week.
The disk library we have right now is approx 50TB.
Is there any best practise that would favour NAS/network storage for the disk library over filling the PowerEdge with large SAS disks?
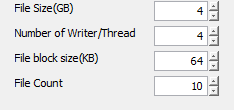
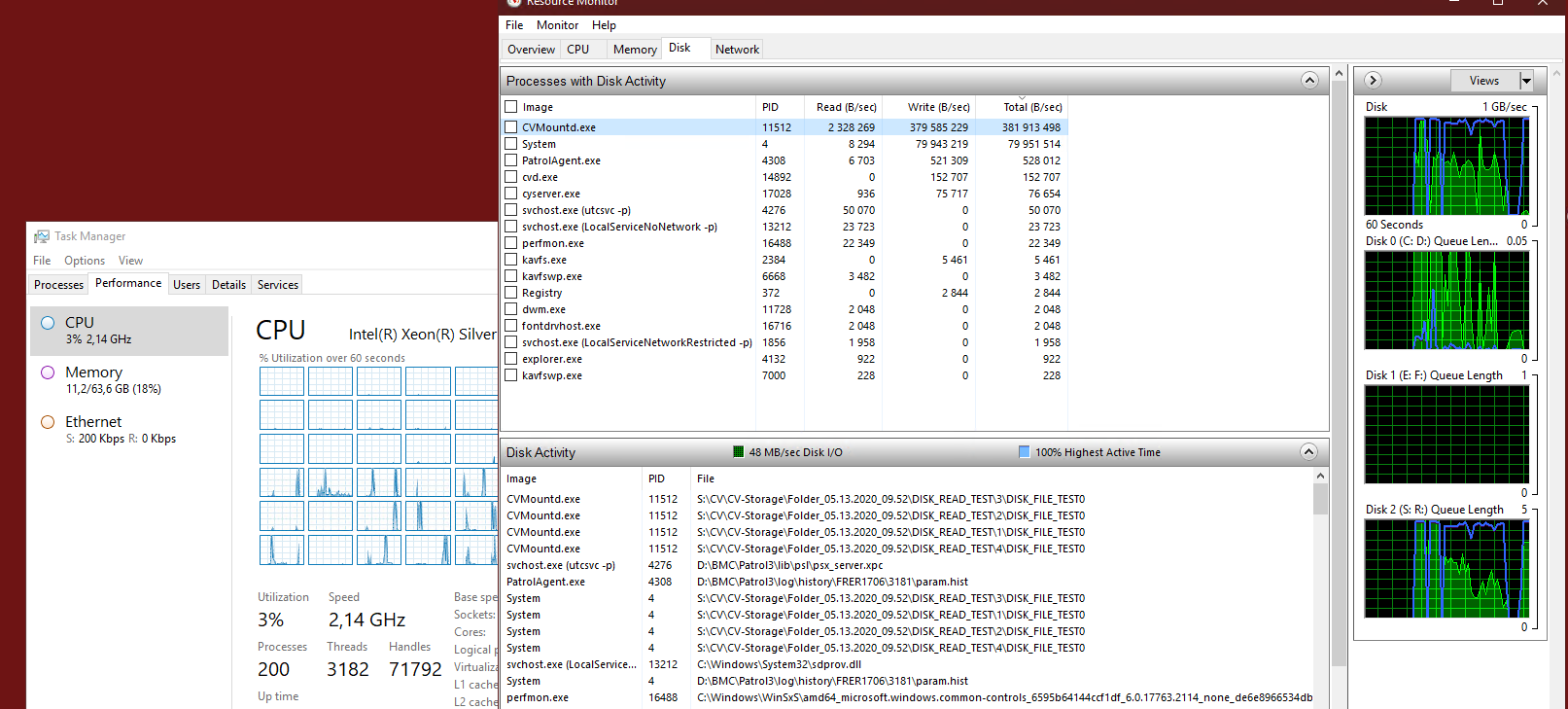
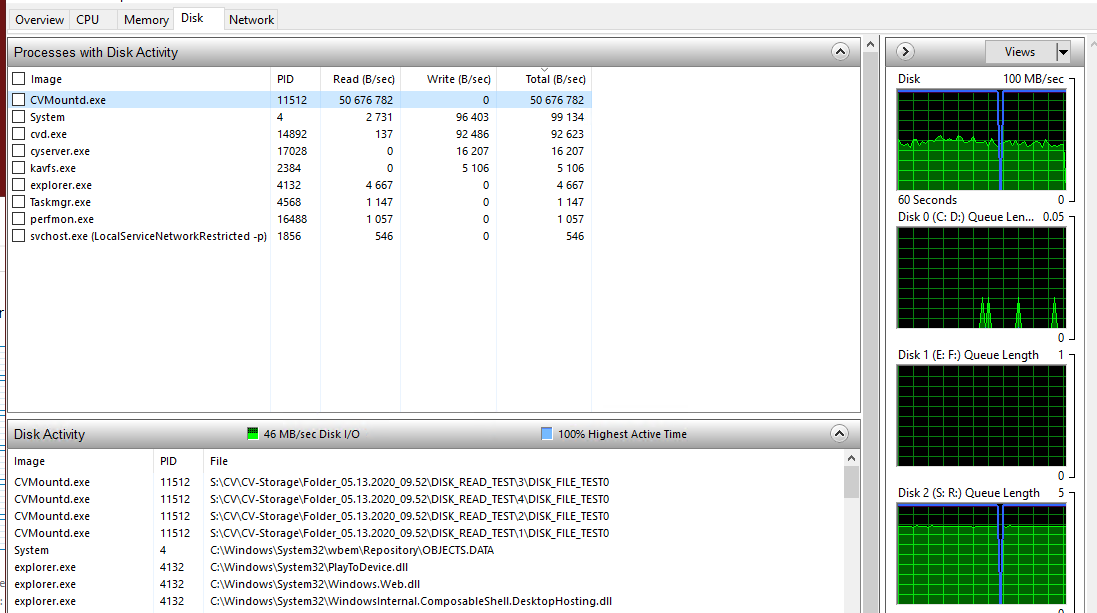
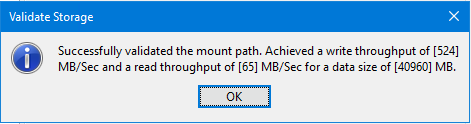
With local disk on Windows Server is there a preference between NTFS and ReFS and is there a best practise over mount path size as we’re currently using 4-5TB mount paths carved out as separate Windows volumes on a single underlying hardware RAID virtual disk.
Given modern hardware performance can anyone see a definite reason to do any more than buy a single PowerEdge for this other than redundancy/availability of backups?
I’m trying to balance robust with simple ![]()