Hello
I have an issue related to DDB
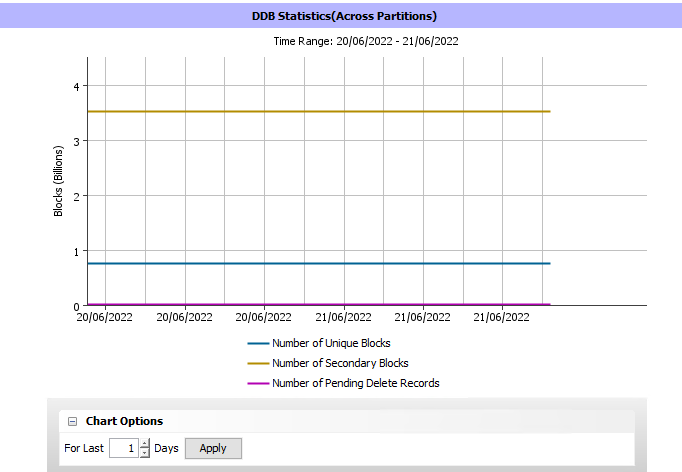
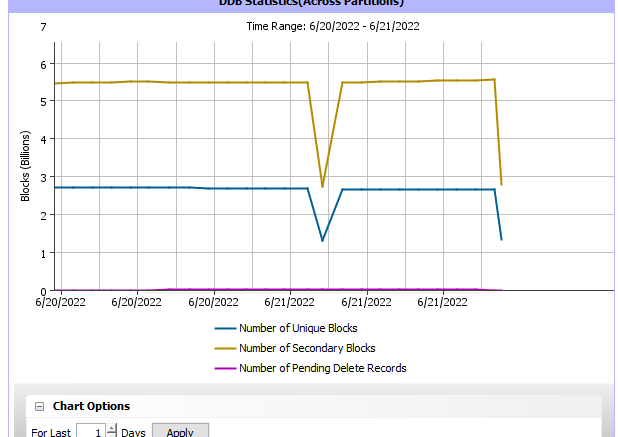
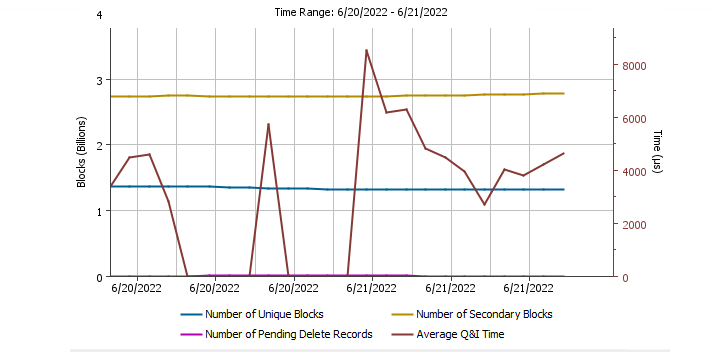
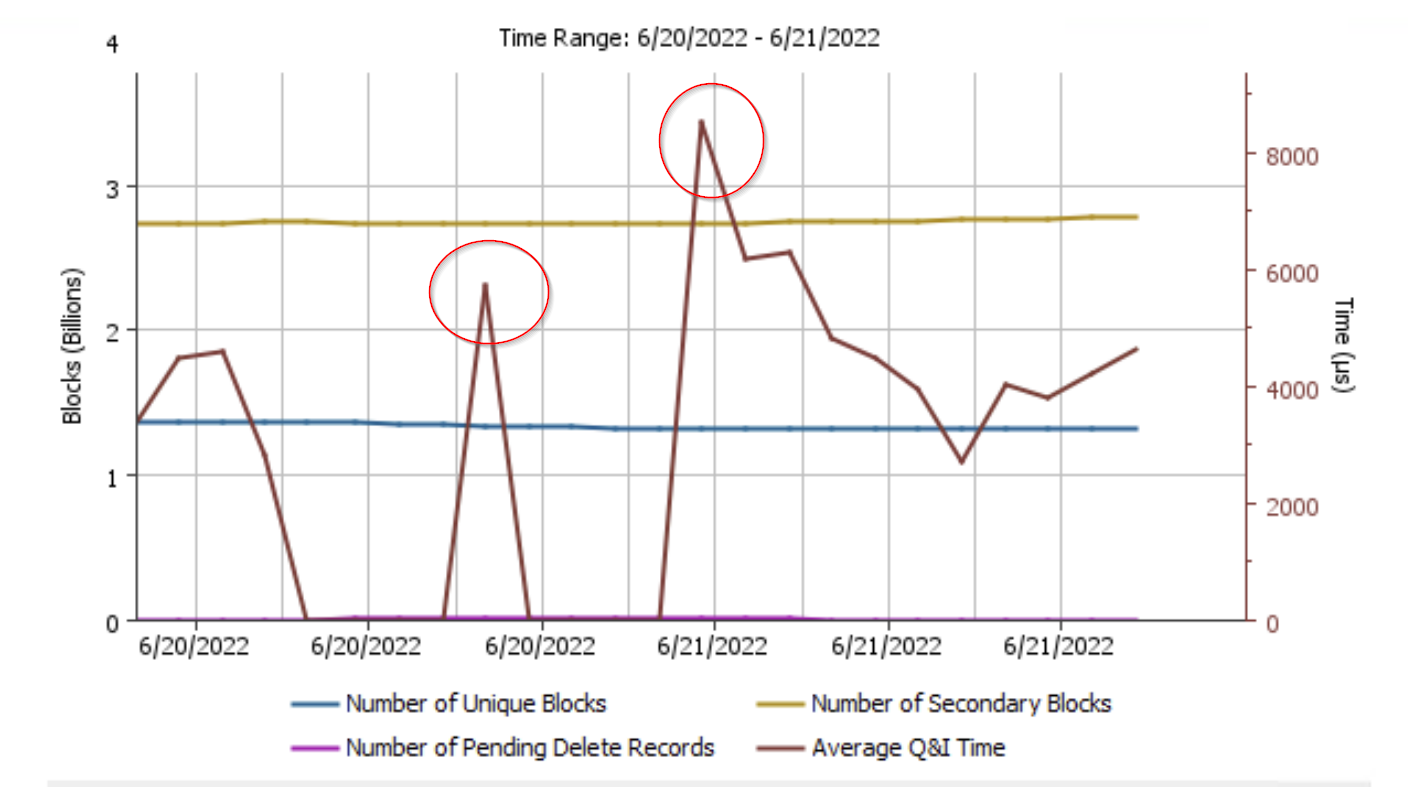
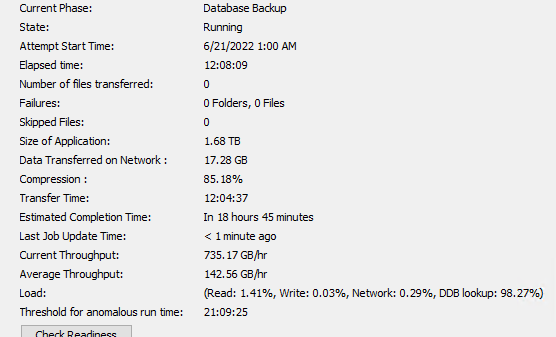
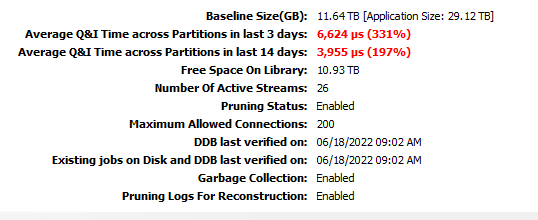
as shown below the q&i time is very high, known that the media agent is serving Oracle and SAP dbs only with daily full backup
around 23 oracle rac and 18 sap client.
library is from flash storage.
DDB Disks is ssd and moved to pure storage [ NVMe disks] due to insufficient space on local disks
any idea how to maintain this ?
Best answer by J Dodson
View original