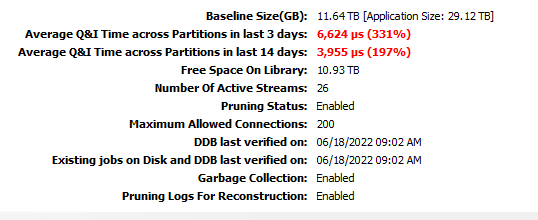
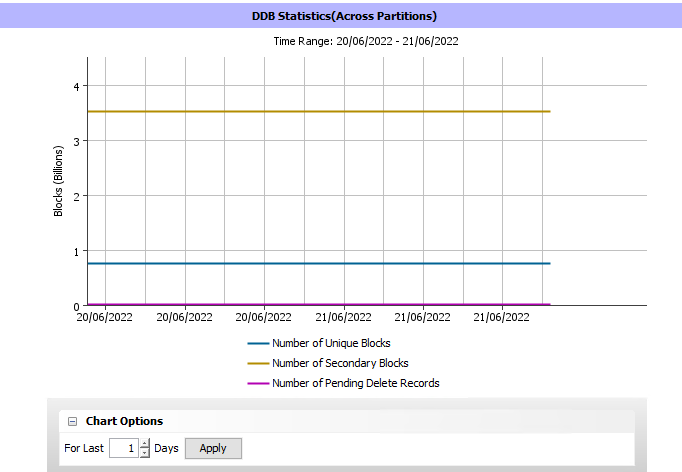
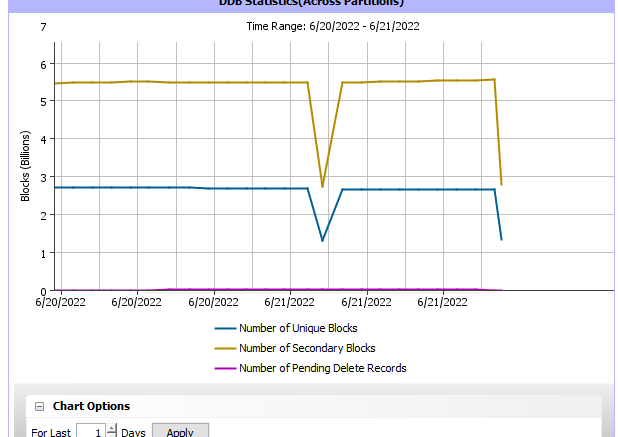
One additional point to this discussion, how many DDB partitions for any and all DDBS reside on this particular mount path/disk? With DDB v5, Commvault will spawn new DDBs if parameters are met for high QI times or a large number of unique blocks so that could spread more work across the disks and if this disk is a DDB target for other DDBs then it could be a contention issue on the disk at the disk level.
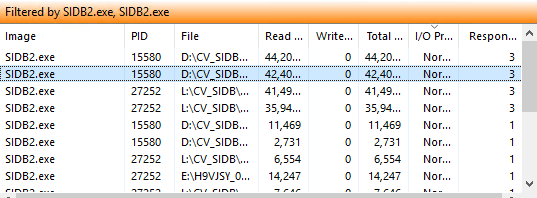
You can check this by looking at Resource Monitor, if this is a Windows MA, and look at the disk queue depth for the disk during these spike times of QI times. It may be necessary to distribute those DDBs to other disks/mount paths.
Also, I have had extensive first hand experience that moving from local NVMe disk to Pure luns, both ISCSI and SAN attached will NOT elicit in any way similar and definitely not better performance. My own experience is about a 30-40% minimum drop in performance and latency, Pure itself is solid performing storage solution, but the DDB lookups are just too intensive for using a shared controller and no one could afford to dedicate a Pure array specifically for the DDB operations.
Another contributing factor could be Commvault operations that would compete for resources such as Data Aging(check for activity on SIDBPrune and SIDBPhysicalDeletes logs as to when they are running at the time of backup for these servers). Data verification operation, or Space Reclamation operations, both of which would have job histories. These operations would negatively impact backup operations if they overlapped.