Hi all,
after some time we are facing another serious issue. There is no available space on the disk library. Ayayay.
We have tried to find if there are any unprunable jobs. There were some of them and therefore we have set option to ignore cycle retention for disable subclients. Unfortunately, only small amount of GBs have been aged.
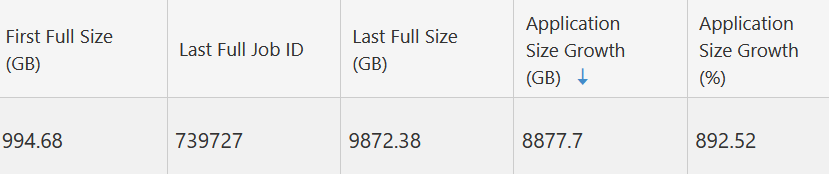
Now, there is a question what to do next. I have no idea how to find what can be deleted in order to make more free space for the backups. Moreover, there will be quit a big deduplication ration, so even manual deletion of some jobs do not have to be useful. Maybe, one useful information can be that during the last month there were increase in data cca 10TB, which is 10 percent increase. Is there possibility to figure out what data did this increase?
Is there any generule rule or useful tool within the Commvault to fight with this issue?
Best answer by Mike Struening RETIRED
View original