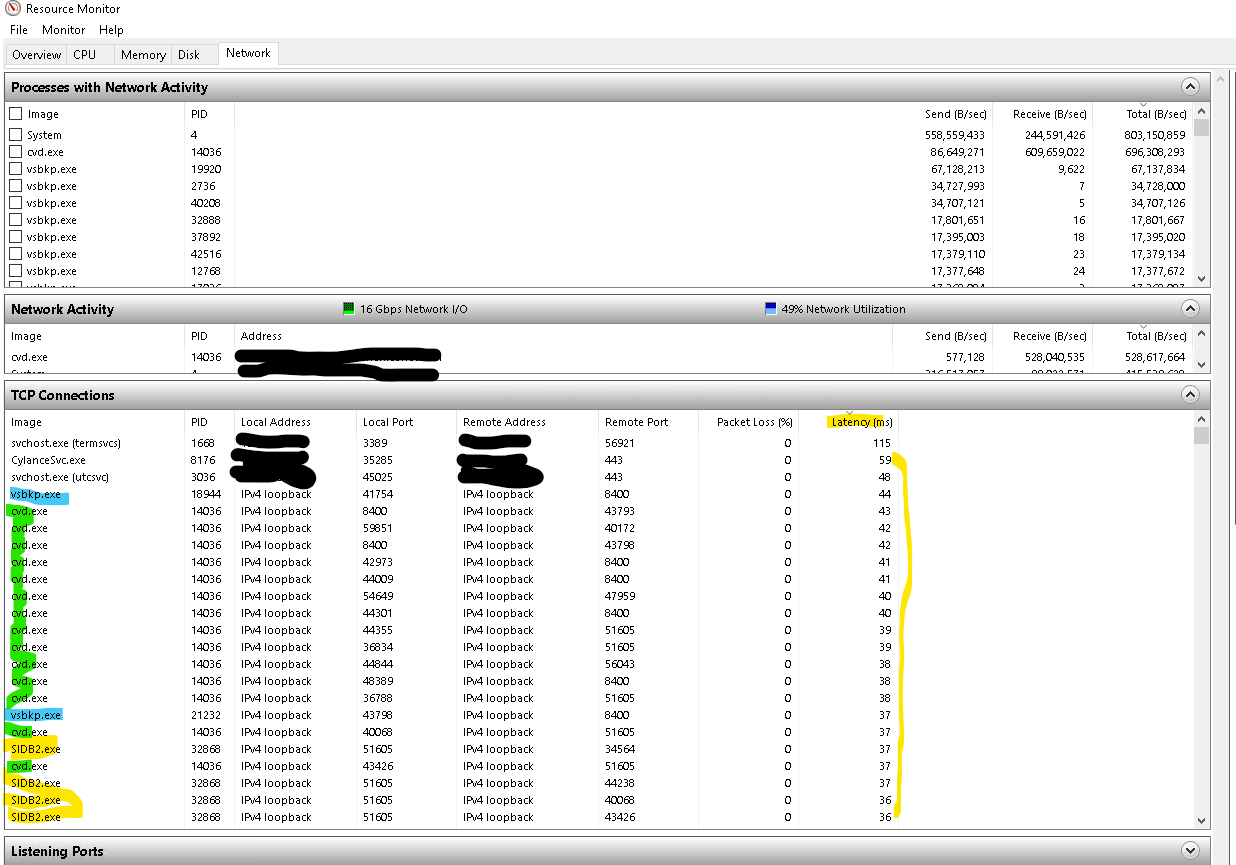
On CV 11.20.9 we backuped Oracle DB from SPARC Solaris to MA RedHar8.4.
If we set “Optimized For concurrent LAN backups” on MA then speed = 1800 GB per hour, if we unset “Optimized For concurrent LAN backups”, then speed=5500 GB per hour.
All other settings are identical.
What changed in MA configuration when set “Optimized For concurrent LAN backups”?
Best answer by AKuryanov
View original