Hello,
can someone explain, how DDBs are queried, if new DDBs for a specific purpose are created ?
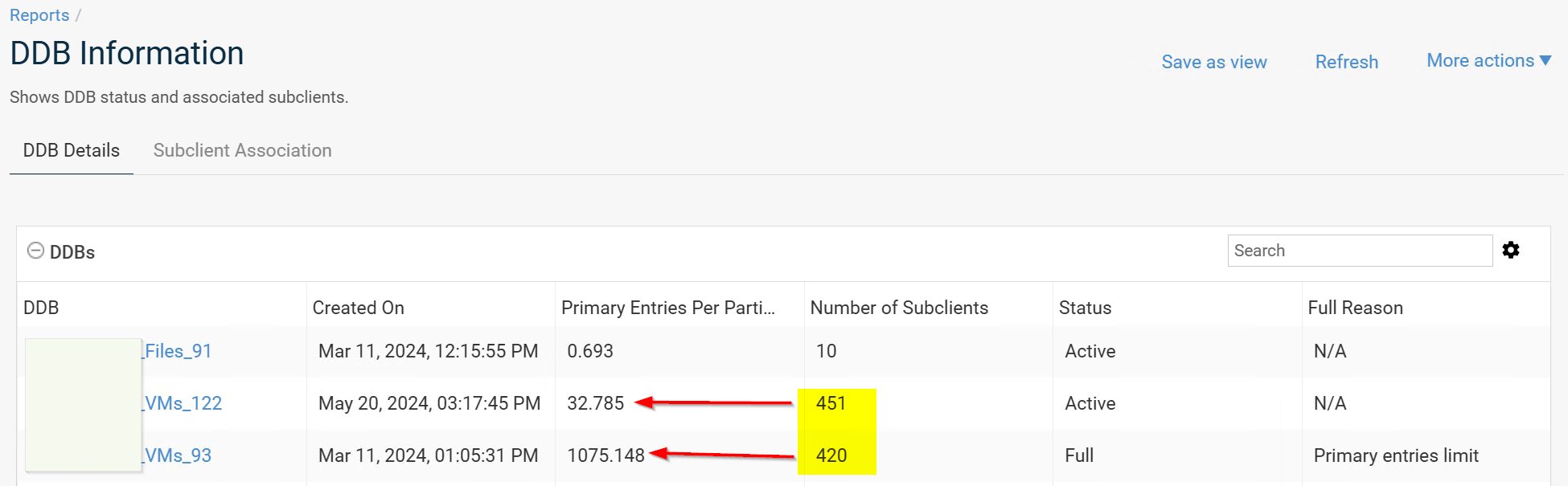
Looking at the figures below, the VMs are leveraged among both DDBs, while only the initially used DDB has a severe amount of primary hash references.
I know, that a new DDB is created and subclients are reassociated if a DDB reaches its limits (Q&I time and/or # of hashes), but I always assumed, that after the reassociation, some of the data is again identified as unique.
The picture below let me assume, that old references are still honored and only new hashed are added to the currently associated DDB. If this was true, a new horizontal DDB does not automatically require additional space in the backend.
thanks
Klaus





