On all of our storage plans we have an auxiliary copy that is uploaded to an S3 bucket, we have been doing some DR scenario testing recently which has involved failing over to our CS server in AWS.
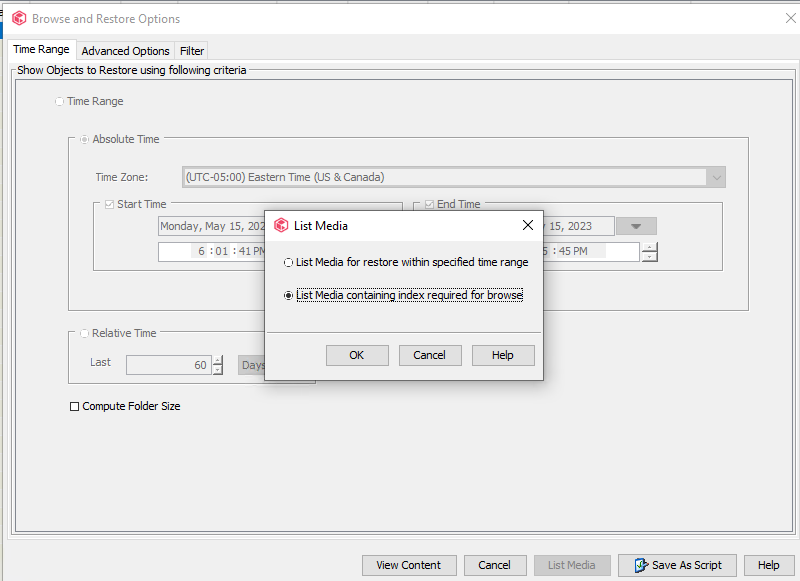
How does the indexing work when doing a browse and restore operation? We have no index server in AWS however for the restores i’ve tested (when using the S3 data copies) it appears to be running a restore job & completing successfully, is the indexes stored in the s3 buckets?