Good morning
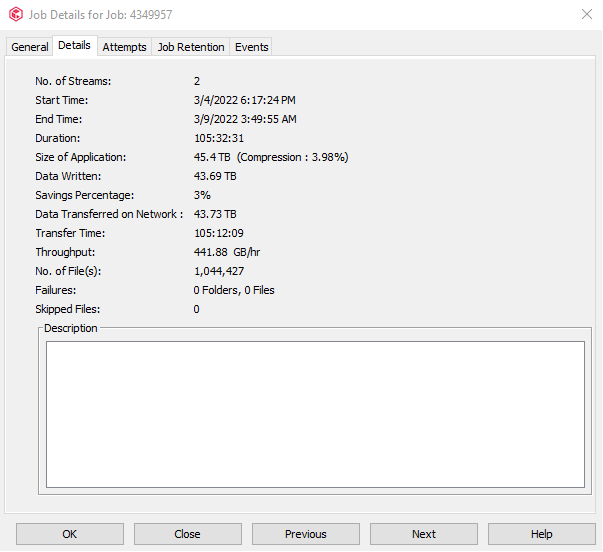
I have a customer that is backing up in car videos (local sheriff’s dept) and he is deduping this data. We have created a new stand alone dedupe database for this data and are using a selective copy to copy weekly fulls to another target. We have set up another stand alone dedupe database for this copy. The customer is having issues getting this data copied over - it’s taking multiple days. The full backup is about 40 TB in size. We have recommended not using dedupe for this copy, but the customer does not have enough capacity for non-deduped copies. Are there any optimizations that can be made to speed up this aux copy? They currently have only 1 subclient backing up all the data - if they split this out, would that help in using multiple streams for the aux copy? Any other suggestions?
Thanks