

We require 1 million objects to be ingested from MS SQL into our cloud storage via Commvault. We created a table with 5 million rows of data in MS SQL but when we perform full backup from Commvault we could only see 20 objects being ingested. Could you suggest us any way how we can simulate 1million objects
Solved
Can we Customize the object count or Chunk size of each object that will get uploaded to cloud
 +4
+4- Apprentice
Best answer by Damian Andre
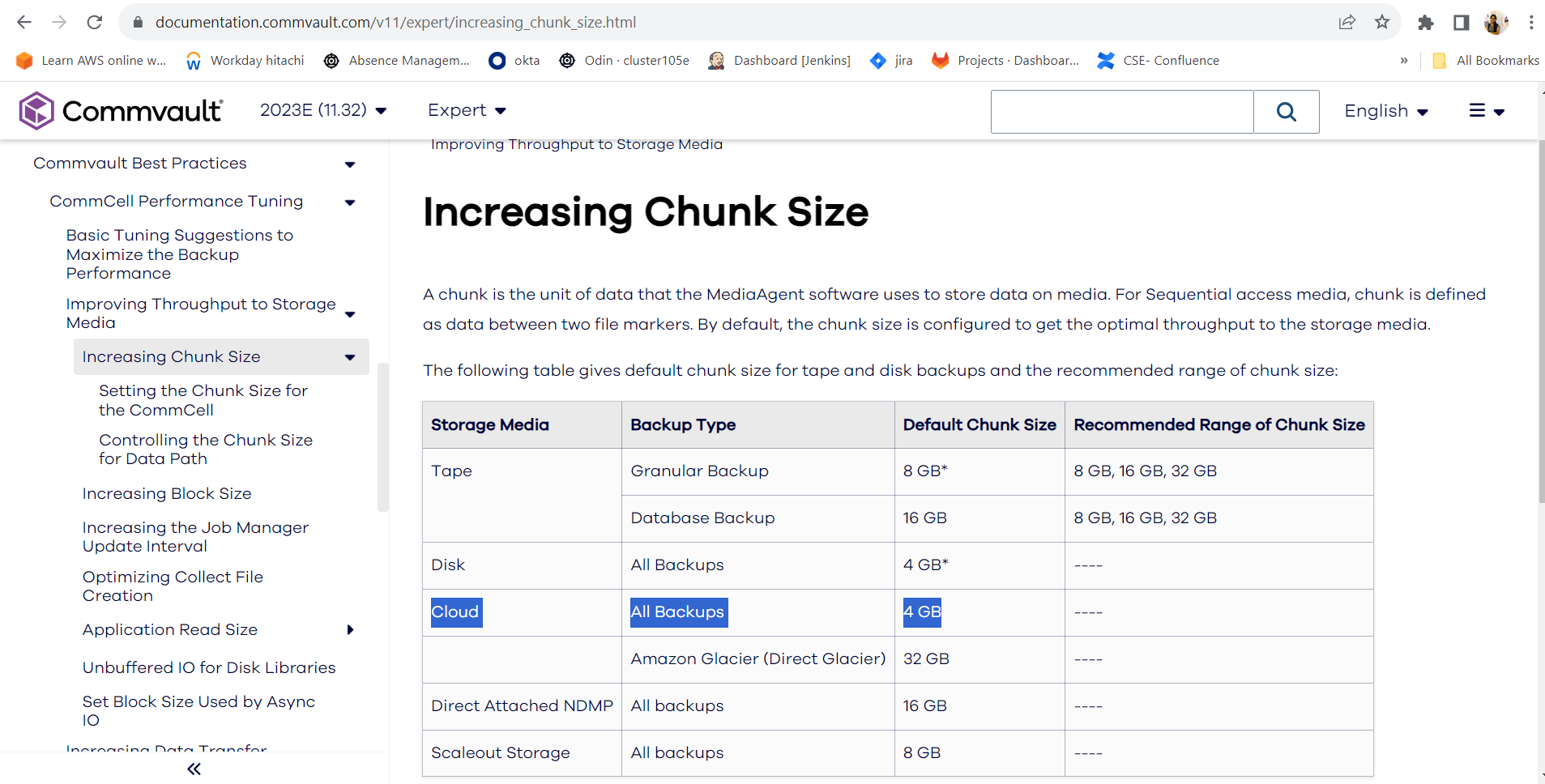
With deduplicated data, the max object size in cloud libraries is 8 MB, non-dedupe its 32 MB. This is not end-user configurable
So you’d need 8 TB of non-dedupable data to get 1 million objects created by Commvault - the type of data or source of the data doesn't impact how many objects are written and what size



Readiverse Academy Certifications

Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.