what does it happen when an auxiliary copy job is suspended and then resumed?
I know this sounds like a strange question but comes from the following experience. We have auxiliary copy jobs that take a long time to be completed and often they are still running when new content is added.
In this case (new content added) the values of Total Data to Process, Number of Readers in use and Current Throughput are not updated in the Job Controller and, even more serious, they remain the original ones for a long time.
If I suspend the aux copy job and resume it right after, all the values are recalculated, a much higher number of Readers are allocated and the aux copy goes much faster.
Is this normal? I mean, I expected that the load resources were recalculated periodically but it looks like it doesn’t happen.
Thank you in advance for your help
Gaetano
Best answer by Collin Harper
@Gaetano
You can try this setting. If this doesn’t help it may be best to get a case opened with Support to make sure there are no resource issues.
Minimum interval in minutes for picking new data for Scalable Resource Auxiliary Copy job
Definition: Specifies the time interval to check for any backup jobs completed during an auxiliary copy operation
Default Value: 45
Range: 15 to 360
Usage: For better performance and efficiency, you can enable the feature to check for any backup jobs completed during an auxiliary copy operation at defined time interval and include them in the replication. To turn on the feature, enable the Pick new data for Scalable Resource Auxiliary Copy job parameter in the current Auxiliary Copy tab.
In this parameter, specify the time interval to check for backup jobs completed during an auxiliary copy operation.
The behavior you are seeing is most likely coming from Dynamic Stream Allocation and Scalable Resource Allocation. These two features modify how streams are allocated between jobs in attempt to achieve the best throughput of all active jobs rather than allowing one or a few jobs to “hog” streams.
As the aux copy gets nearer to the end, less streams are re-allocated back into it to leave resources available for other jobs. Suspending\Resuming re-calculates the remaining data and assigns new streams.
Issues with this old design (Non-Scalable Resource Allocation)
AuxcopyMgr would lock all the resources allocated to it by JobManager for the entire duration of the job.
When large number of aux copy jobs were running or the individual aux copy jobs were very large it would cause other jobs to go into hung state. This was because the JobManager process would waiting for AuxCopyMgr to populate the table with chunks for all the jobs chosen. This process would use a lot of CPU/RAM/DiskIO on the Commserve. For some customers, there could be 500K+ jobs and 1M+ chunks waiting to be populated. When JobManager was waiting for AuxCopyMgr it would be unable to process requests for other jobs and therefore other non-Aux Copy jobs would go into hung state.
Benefits and Behavior when using Scalable Resource Allocation.
With this new Scalable Resource Allocation framework, stream reservations are now only done for tape copies. This is because for tape copies we need to ensure that no other resource is trying to access the tape at any given time. For reading from disk copy, we don't need to make these reservations as we can have multiple streams accessing the data at the same time. As a big part of the problem with the old framework was resource allocation causing locking on the job manager process; not having to create reservations for disk aux copies greatly helps with the issue of other non aux copy jobs getting hung.
If the coordinator MediaAgent goes down the job will fail the attempt and then retry 20 mins later using alternate MediaAgent as the coordinator.
With the old framework the archChunkToReplicate table could grow extremely large and cause JobManager to freeze when it was being populated.
The new framework helps as now we are able to just populate with 1000 jobs (default) at a time. This 1000 jobs default can be changed in the aux copy advanced job options (seen below). Copying only 1000 jobs at a time helps us avoid situation with old framework where JobManager gets locked for very long period of time and causes other jobs to go pending.
Another benefit of the new framework is that we can set the Aux copy job to only copy jobs from a select time period. In every stream we will try to pick the oldest chunk to copy based on the Chunk Id.
Allows us to check for and pick new jobs whist the batch of 1000 jobs is still processing. This will utilize the existing stream count that was reserved and therefor help avoid situation found with old framework where single job is left with low throughput and copying just 1 large stream. The period on which the new framework checks for new jobs can be altered here:
This 'Pick new data for Scalable Resource Auxiliary Copy job' setting also needs to be picked in order for new backup jobs to be picked up for aux copy whilst aux copy is already running.
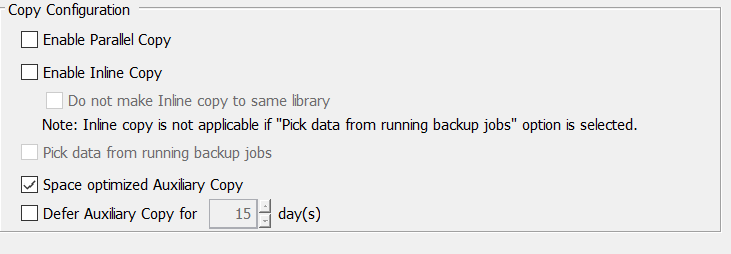
You also need the 'Pick data from running backup jobs' setting enabled for this to work.
I know this is a lot of information to throw at you but I hope it helps. Let me know if you have any further questions.
Going through the bullets, I am afraid that what’s explained here is not happening
Allows us to check for and pick new jobs whist the batch of 1000 jobs is still processing. This will utilize the existing stream count that was reserved and therefor help avoid situation found with old framework where single job is left with low throughput and copying just 1 large stream. The period on which the new framework checks for new jobs can be altered here:
Readers are decreased near the end of the aux copy job but then new jobs are added, coming from the ongoing backups, readers are not increased again. At the same time, the new jobs are actually added because the aux copy keeps on running. I checked this for about 12 hours.
Here is the global setting
and here the aux copy settings
Pick data from running backup jobs is grayed.
Consider also that this aux copy is a Selective Copy as it includes only the weekly full.
Pick data from running backup jobs is off by default. This will copy data blocks from backups currently running, not check if any jobs are available to be copied (jobs that have completed since the last check).
You mean that, with the settings above, new data from running backup jobs are not included in currently ongoing auxiliary copy, correct?.
What about jobs that have completed after the start of the aux copy? Will they be picked? If yes, I expect that the detail data about the aux copy are updated to take them into account, when does it happen?
Correct, blocks from running jobs will not be copied. Only jobs that have finished by the time the aux copy does it check at 99% will be added to the aux copy job.
Given the scenario you describe, when will the values of Total Data to Process, Number of Readers in use and Current Throughput be updated to take into account the newly added jobs?
I see that they remain unchanged for quite a long time and this is a bit misleading.
These should all change after we check for new data. Say the aux copy is 100Tb and we copied 99Tb, the check will occur and say 20Tb has been added. The job will report 120Tb to process and the “% complete” should drop down accordingly.
this is exactly the key point. It looks like this check doesn’t occur because I see the values in the Commcell Console unchanged for a long time.
I mean the “% complete” remains 99% for 10-12 hours and more, along with Total Data to Process, Number of Readers in use and Current Throughput. None of them is actually updated to take into account the new jobs being added.
Is there any configuration parameter determining the update interval?
Minimum interval in minutes for picking new data for Scalable Resource Auxiliary Copy job
Definition: Specifies the time interval to check for any backup jobs completed during an auxiliary copy operation
Default Value: 45
Range: 15 to 360
Usage: For better performance and efficiency, you can enable the feature to check for any backup jobs completed during an auxiliary copy operation at defined time interval and include them in the replication. To turn on the feature, enable the Pick new data for Scalable Resource Auxiliary Copy job parameter in the current Auxiliary Copy tab.
In this parameter, specify the time interval to check for backup jobs completed during an auxiliary copy operation.