I noticed a new alert was added to my CommServe and I believe this was after an upgrade we did recently to a new FR.
The alert in question is : Alert Data Verification Failure Detected and it is briefly discussed on the link.
https://documentation.commvault.com/11.20/expert/12395_data_verification_faq.html
Few things that come to mind and not completely clear to me.
- The alert says that it detected corrupted data on backup disk. It does not tell me the job id nor the path. Looking at the alert in the GUI, It also does not have any additional option to be selected such as job id, storage policy etc. How come?
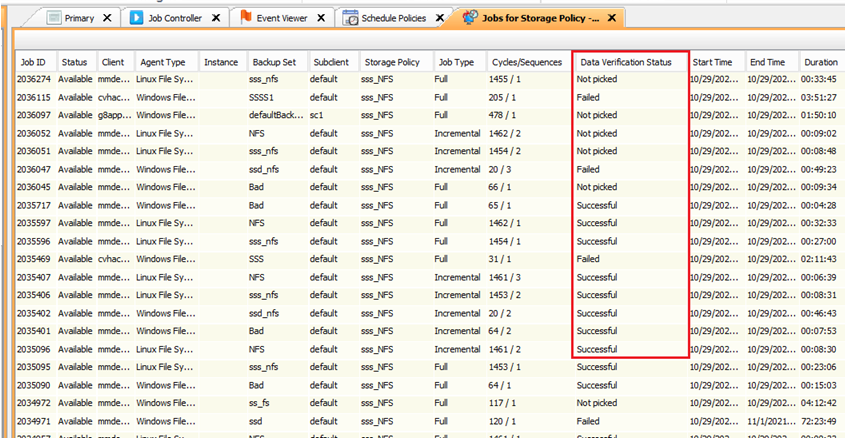
- Job history to the subclient or storage policy brings everything green and no issues with the job themselves. My understanding is that I would potentially have issues trying to restore the particular subclient up to the specific transaction log. Why would job history still shows the job as succesfully completed?
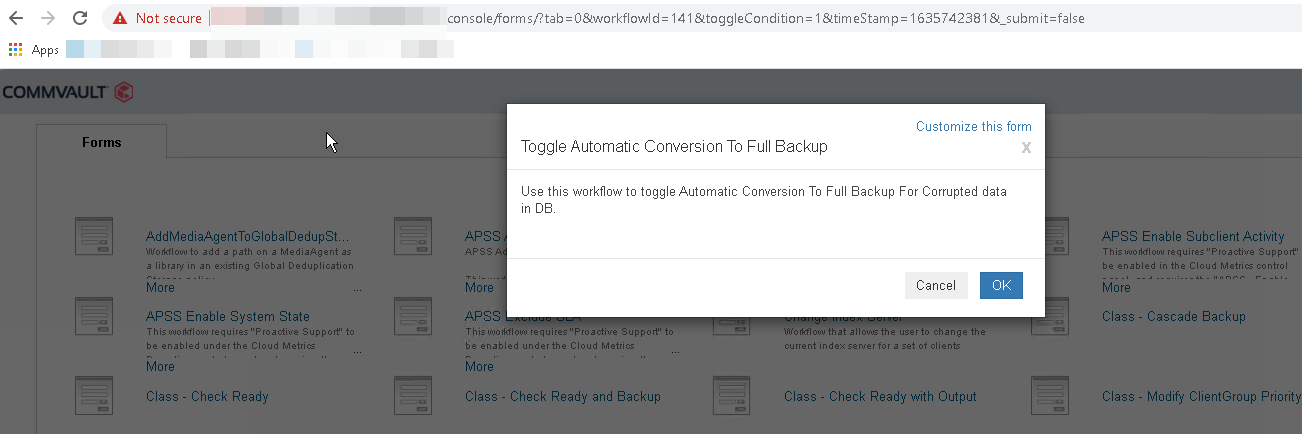
- The alert gives you two options, one to convert the subclient to full during the next backup and one to automatically convert all failure verifications to full. The link points to a workflow to be executed, but upon searching the workflow in the Commvault Store under workflows I can`t find anything related. What are both workflow names? how can I find them?
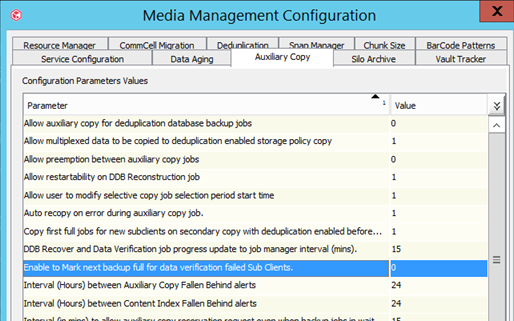
- On my storage policy Data Verification is disabled. Trying to understand the alert considering that the option is disable?
- Was this alert introduced in recent FRs? which one specifically?
Appreciate the time.