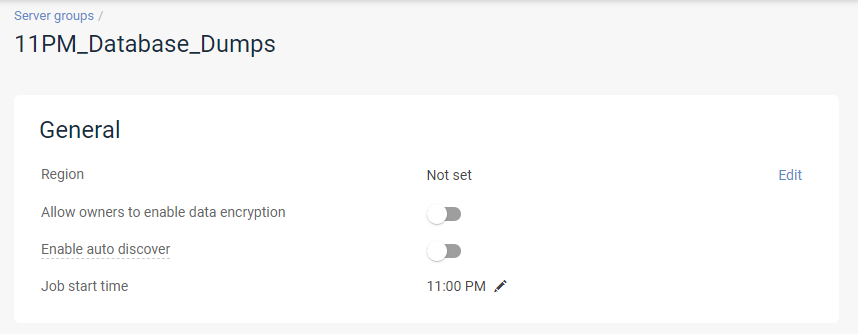
Each plan should have a corresponding storage policy in the Java UI so there shouldnt be a 1 to many ratio, unless many plans have been deleted, or you are using region based plans.
Lets ignore what we see in Java UI for a minute.
A server plan is an encapsulation of; Name, Storage Target , Retention, backup frequency, schedule, content to backup (for FS) and options, snapshot options, and database options, all rolled into 1 “container”.
Lets break each aspect down, ill colorize some of the words to draw attention to them as they are either labels in the UI or terms that need focus. We will start from top to bottom on the create server plan window.
Plan name is the friendly name of the plan. I always recommend using a name that is descriptive to talk about what its for, what storage, and maybe frequency. Something like Daily_FSVM_Netapp_MCSS_30_90, so I know that its my daily FS/VM plan, that writes to my netapp, secondary to MCSS (Metallic cloud storage service), primary retention is for 30 days and MCSS copy for 90.
The storage target and retention are part of the “Backup Destination” section in the plan. This is where you tell the backups were to go and how long to keep them. You can also enable extended retention rules here if you need to keep certain aspects longer. The retention also has as role in the schedule, we will get to that in a minute.
The next part is RPO, this is your “schedule”. This is the incremental backup frequency in minutes/hours/days/weeks/months/years, along with the start time. This allows you to control how often and when backups can run. This can be further isolated to days and times via the “Backup window”. A “backup window” controls when the backups can run on a plan level. Similar to a “Blackout Window” which can be applied on the cell, company, server group, level. Under “RPO”, you can also schedule traditional Full backups, with corresponding options, and windows. Remember when i mentioned that the retention has a role in the schedule, this is where the automatic synthetic full gets its schedule from. In order for a cycle to close and for pruning to remove older backups based on the retention the cycle, we must run full or synthetic full (as a cycle is considered Full to Full). So when you create the plan and set the retention, the synthetic full backup schedule is aligned to that timeframe. This is how we close cycles in the event you never run traditional fulls.
The collapsed “Folders to backup” is your content to backup for file systems. This by default is everything, but also allows you to filter files, folders, patters, and control system state options and other components. Say you wanted to specifically run a backup for a single folder that exists across your entire file server estate. You can control this from a single plan using this method.
The backup “snapshot options” section allows you to control recovery points, their retention and enable backup copy operations and runtime. I would recommend you venture into BOL for more details on that, as I dont think it will pertain to the summary of this post.
Finally, the database option which allows you to control log backup RPO and you want to use the disk caching feature. For databases instead of using the regular RPO option, translogs usually have more aggressive protection needs, so this option controls when translogs get protected.
With the understanding of these foundational aspects, when looking to consolidate, start with least restricted needs of machines that need to go to a storage target. That should be one plan. As requirements for run time, backup type, or storage targets change, those would require an additional plans. This should help narrow down the scope of what needs to stay, and what may be overlap.