On CV 11.20.9 we backuped Oracle DB from SPARC Solaris to MA RedHar8.4.
If we set “Optimized For concurrent LAN backups” on MA then speed = 1800 GB per hour, if we unset “Optimized For concurrent LAN backups”, then speed=5500 GB per hour.
All other settings are identical.
What changed in MA configuration when set “Optimized For concurrent LAN backups”?
Best answer by AKuryanov
After a long correspondence with support, it was found that on RHEL8 during backup with enabled compression, the network traffic from the client to MA does not decrease. Those, we see that on RHEL8 the network traffic is 2 times higher, and the backup time is 2 times longer compared to RHEL7. The reason for this has not yet been clarified.
Hey @AKuryanov , appreciate the question! You are behind on Maintenance Packs, though I’m not seeing anything specific to this feature in any of the release notes.
I’ll tag in some Oracle and Media Management folks for advice.
There are two major areas that get impacted when toggling this setting. This is a confusing topic, so bear with me.
#1 - That option changes the way data is transferred between Commvault processes local to the media agent. This option is also sometimes referred to as SDT (simple data transfer). With “Optimized For concurrent LAN backups” ON (i.e SDT ON), data is transferred from one process to another using the loopback adapter (i.e 127.0.0.1 in most cases). Each process binds to a port on the loopback and uses TCP to send data. If this option is turned OFF (SDT OFF), it uses shared memory to transfer data between processes. I.e data from the client is receive to the Media Agent (lets say on the CVD process), and then the writer process may be CVMA, so CVD puts the data into memory, and CVMA reads it out. I’m not 100% sure if that is the correct scenario but the takeaway is that it does not use the loopback and TCP connections to communicate between processes on the MA if you disable optimize for concurrent lan backups. As you can imagine, this setting could increase memory usage and lower scale, which is why SDT is on by default. It may be worth investigating performance of the loopback adapter to ensure it can transfer data fast (like, gigabytes/sec fast) using a tool like iperf3.
#2 - now, if you disable optimize for concurrent lan backups (SDT off), it also changes the way the client communicates with the Media Agent - especially so if you have a network configuration in place restricting ports. I am a bit rusty on this, but with optimize off (SDT off), I believe data will bypass any firewall tunnels (i.e sending control traffic and data over an established tunneled connection - typically 8403) - it will send control traffic over the firewall tunnel but send DATA traffic directly to the CVD port on the Media agent (i.e 8400). This sometimes offers huge performance especially if you are choosing to encrypt traffic over the network tunnel in the networking options. Of course, disabling SDT bypasses network encryption so be aware of that.
One way you could test this out is to keep optimize for concurrent lan backups ON, but add 8400 as an additional port in the network/firewall configuration. This will bypass the network tunnel for data traffic (with the encryption caveat I mentioned before). Another option if you are using network configurations is to increase the ‘tunnels per route’ option discussed in the second post in this thread. Disabling SDT allows the ‘additional data ports’ networking option to be used, that option is ignored when optimized for concurrent LAN backups is ON.
So the TLDR; You could have a performance issue with the loopback adapter on the media agent, OR you are bypassing some of the firewall protocol and encryption overhead which in-turn is improving the performance - especially on unix clients, disabling SDT allows additional port usage which can benefit some environments.
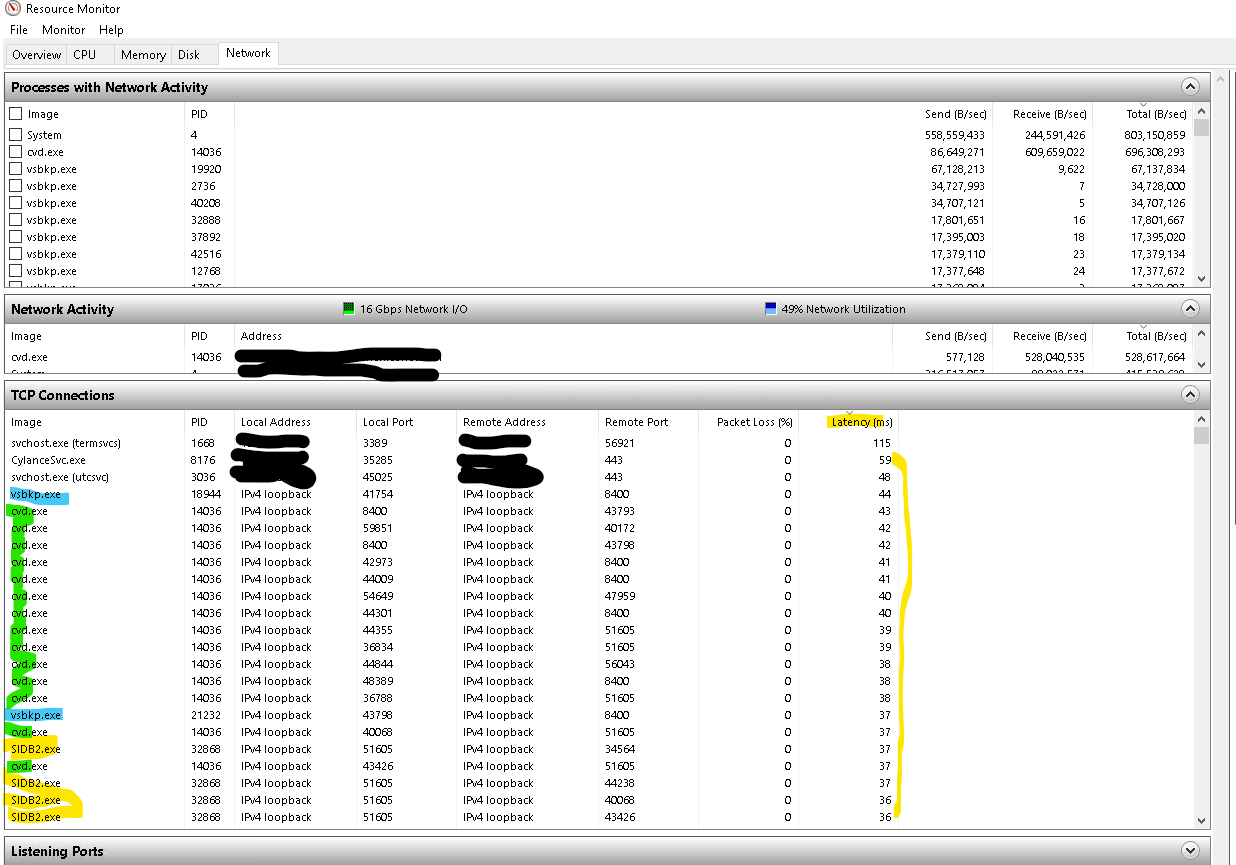
This post has me fascinated. It mentions the loopback adaptor. We do have Optimize for Concurrent LAN backups enabled and we see 40ms latency and higher on the Loopback adaptor in Windows resource monitor. In one of our support tickets we were told that the loopback is not used that much so it should cause an issue. Reading #1 it makes me think that maybe there is more to this. I am nervous to make any change and unchecking the optimize box as the Media agents move a lot of data.
This post has me fascinated. It mentions the loopback adaptor. We do have Optimize for Concurrent LAN backups enabled and we see 40ms latency and higher on the Loopback adaptor in Windows resource monitor. In one of our support tickets we were told that the loopback is not used that much so it should cause an issue. Reading #1 it makes me think that maybe there is more to this. I am nervous to make any change and unchecking the optimize box as the Media agents move a lot of data.
I will need to think about this more...
Loopback is absolutely used a lot, it is the way commvault processes communicate with each other by default as mentioned above. I’m not really sure latency is such a big deal though - the only latency sensitive part of the product is deduplication - signature checks in/out affect overall performance, and latency there is often mitigated by parallel transactions etc. Q&I time monitors all that so as long as its below the threshold it should be good. For other areas of the product its really bandwidth that makes the difference.
Regarding the “optimize for concurrent lan backups” option, you can toggle it freely, it only takes affect on a NEW backup, so its perfectly safe to disable it, run a test backup, and immediately re-enable it as a test - No issues with that. In fact, I had a REALLY strange case years ago where an auxcopy would only be performant with it disabled, so we created a workflow that disabled it before starting the auxcopy job, and re-enabling it after the job started. It was just a temporary workaround while the customer moved to new infrastructure.
@Damian Andre I am trying your idea, I have a AUX copy that has 1 - 20TB backup to work on. The source backup is on a - 4 node GridStor with Global Dedupe. The Target is a 2 node Grid with Global Dedupe. The WAN in between is 10gb with 32 ms latency. The AUX was running around 700 GB/hr. I killed the AUX and unchecked the Optimize for concurrent LAN option on the 4 source media agents. Starting a fresh AUX copy it is now running around 600 GB/hr. So for the AUX it does not look to different with or without the Optimize on the source MA’s. The Target MA’s do not have the optimize option selected.
The 20TB backup is highly de-duplicated, so I would expect it to run much faster, as it is all DDB lookups and updates. This same backup is also being written to a LTO7 tape drive and that is bouncing between 800 and 2,700 GB/hr.
I am a bit confused how the Tape AUX can run faster, (physically writing all that data to media) vs dedupe to dedupe AUX over the WAN with lots of DDB lookups and updates.
The performance hunt continues.
Thank you again for the idea. I apologize for taking this thread on a bit of a detour.
. I killed the AUX and unchecked the Optimize for concurrent LAN option on the 4 source media agents. Starting a fresh AUX copy it is now running around 600 GB/hr. So for the AUX it does not look to different with or without the Optimize on the source MA’s. The Target MA’s do not have the optimize option selected.
I believe that its on the target MA you want to try toggle it, since the destination controls the transfer type. So perhaps try the target MA(s).
I will try that tomorrow, I suspect that job will still be AUX’ing In the meantime, I grabbed a Resource monitor screen shot of 1 of the 4 core media agents while the backups are running tonight.
@AKuryanov I'm amazed that you are still running on a very old maintenance release. It is 13 months old! The list with documented fixes and enhancements is huge! Please consider updating your environment!
@Onno van den Berg Over the years of using CV, we realized that it is impossible to patch the infrastructure of several thousand clients once a week (64 patches in 56 weeks).Many patches improve in one place and break in another. And in Enterprise, stability is the most important thing. Therefore, we do not patch until support says that your problem is resolved in that particular patch.
@Onno van den Berg Over the years of using CV, we realized that it is impossible to patch the infrastructure of several thousand clients once a week (64 patches in 56 weeks).Many patches improve in one place and break in another. And in Enterprise, stability is the most important thing. Therefore, we do not patch until support says that your problem is resolved in that particular patch.
I have not said you should patch your systems on a weekly basis, this is b.t.w. also not possible anymore as MRs are released on a monthly basis. But you haven't even patched you environment for more than a year! The version you are running is still close to GA, which means a much bigger chance of underlying software issues that impact reliability, security and most important you fix issues before you run into them while trying to recover data. So I would consider patching at least quarterly! B.t.w. you also patch your Windows systems every month, right ;-)
After a long correspondence with support, it was found that on RHEL8 during backup with enabled compression, the network traffic from the client to MA does not decrease. Those, we see that on RHEL8 the network traffic is 2 times higher, and the backup time is 2 times longer compared to RHEL7. The reason for this has not yet been clarified.
@AKuryanov@Mike Struening so if I understand correctly the issue still persists and was addressed only via a workaround by the use of RHEL7. curious to hear the root cause and to know when this is fixed.
Also wondering if @AKuryanov upgraded his environment to a more recent maintenance release to see if that would sort out the problem.
@AKuryanov , checking this incident again (thanks to @Onno van den Berg bringing thread back up), it looks like this case was archived.
Here’s the archived last step:
Issue: ====== Oracle database backup is having a Slow backup performance on Media agent with RHEL 8.
Work so far ------------ -- dev team advised to run backup with pipeline mode -- added sPipelineMode with value B:P under iDataAgent on client -- above setting provided expected through put for customer -- Customer has several client so created a group for them and added pipeline mode to group -- Additional setting is from client group is now inheriting to individual servers correctly. -- Customer raised another issue , backup performance is good but compression is not working on client on Red Hat 8 version of MA. ( MA with RH7 shows no issue) -- Dev stated ,we are 100% sure the compression is happening on the client. But we do see more data transferred over network. -- Dev advised to check ring buffer parameters on RH8 MA? and to Increase both the RX and TX buffers to the maximum -- After this change Performance increased from 1.5 TB per hour to 3.5 TB using a media agent running the RH 8 operating system -- on a media agent with the RH 7 operating system, the performance will increase to 9 TB per hour. -- Now customer raised that more network interface usage observed with sPipelineMode B:P set ? -- Dev confirmed that it is known issue -- Customer confirmed more network interface is observed with out pipeline mode set on client. -- Logs shows that pipeline mode was used ( cvperfmgr log) even pipeline mode is not configured on client group/ client itself.
Current status (3rd Dec) -------- Waiting on customer to provide new logs from server ( with increased file version for ORASBT) to check from where pipeline mode is getting configured.
So make some changes on Commvault side (sPipelineMode) and making some OS changes improved performance drastically?
I'm really interested to hear if this was a specific case and if not how this has been tackled for all Commvault customers. E,g, is the sPipelineMode set automatically or was the logic itself improved in a more recent feature release and was the OS setting added to the best practices section.
Hello all. We also had performance issues here and there. I did investigation involving CommVault and Microsoft support. It turned out that “Optimized For concurrent LAN backups” makes a huge difference for Windows MA performance, specifically due to enabling of transfers through Loopback interface. There are throughput limitations on loopback interface due to the way OS is processing data (for example it will use only one CPU core for processing). Starting from Win2019, 2021 Microsoft introduced several improvements. In my tests loopback interface throughput on win2012, 2016 had limit of 1.2Gbps. With Win 2019 I was able to get 9Gbps on the same hardware/vm. So at least for Windows it is highly recommended to upgrade MAs to 2019-2021.