


Hey,
This is not the first time this happens to me and every time it is an issue since it fills up the disk and it wont release the space until (at least) I either reboot the media agent or add a advsetting key (CLEANUP_TEMP_DB_DAYS = 0). In this case, particular case, i have done both and still wont release the space.
Long story short, any time I request a browse from a job that is available on disk but is fairly old, the media agent kicks off a Index Restore, since those indexes are not on media agent anymore. The index kicks in, and thats when the operation starts to fill up the disk. (always with NDMP (V2) that are massive).
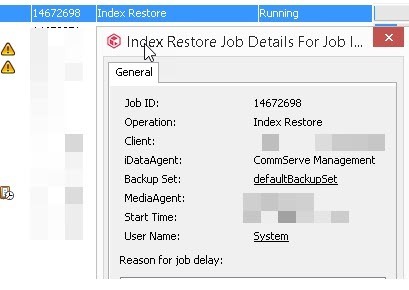
So, I then, I cancel my browse request, but it is too late now, the background tasks will continue to a point where it fill up the disk.
When I look at the three size, I can see the client GUID which just gives us a little bit more info as to which client / confirm the client that cause the problem.
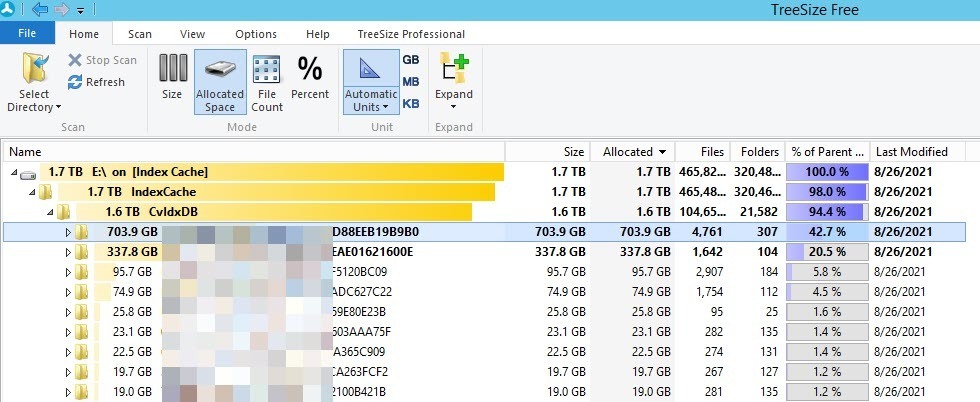
So I currently have a media agent that its all of space for a Browse that was initiated days ago and didnt even actually let me browse due to the operation of restoring the index. So I closed that browse operation yet the Index Restore kept going. Used the key mentioned and restarted the services and still nothing. Tried load balance workflow which was not helpful.
So looking for suggestions, experiences with the same issue and whatever is helpful.


