during regular DR-Tests we see problems with the jobresults directory usage for larger DBs (1 TB+):
Error Code: [30:375] Description: Encountered error while writing to the file. Error code [28]. Please make sure there is enough disk space on [C:\Program Files\Commvault\ContentStore\iDataAgent\JobResults\CV_JobResults\2\0\4455051\RstStage]. Source: Clientname, Process: SQLiDA
CV stages the whole database there, so we must add an additional 3-5 TB disk for that in the DR-Site on each larger machine.
We have also bigger SQL machines which does not consume that much of space in the Job Results Directoy, even when the Jobresultsdirectory size is smaller than the size of DB we are restoring.
Does anybody know why this is different between SQL-Systems?
Best answer by Ron Potts
Thank you Christo for the additional details.
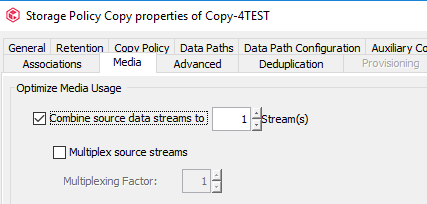
Can you confirm though on that Secondary DASH copy, if you are indeed using the “Combine source data streams” as well?
Can you also confirm how many Streams are configured on the SOURCE during backup?
If this option is enabled, even if the secondary copy you are restoring from is also disk, I believe the IDA still detects that Combine to Streams was used and attempts to rehydrate the data in the Job Results directory.
You can attempt to disable the staging of the data to the Job Results directory on the DESTINATION server using the setting below. This would allow the restore to attempt itself in the traditional fashion without staging the data, but it is important to note that depending on the configuration, (such as Tape, or where we aren’t able to provide SQL with the exact number of streams on restore as were taken on backup) the restore job might fail.
The behavior you are seeing sounds like you are using the option to Combine Streams on an AuxCopy of the data.
Note: If you are performing a restore operation from a secondary copy that has the Combined Stream option enabled, the restored data is temporarily staged at the Job Results folder before restoring it to a SQL Server. You can change the location of the staging folder by changing the value of additional setting sStageFolderAuxCopyRestore.
To elaborate on the behavior a bit -- When requesting a backup from Microsoft, the amount of Streams configured on backup translate into “Backup Devices” on the SQL side. So if four streams are configured in Commvault, Microsoft will allocate four backup devices on the SQL side. If the backup was taken with four streams/backup devices, Microsoft expects four backup devices/streams on restore.
When you use the option to combine to streams, the streams on the return are different and the restore would fail. To prevent this, for the SQL Agent we detect if Combine to Streams was used, and if so, on restore, we re-hydrate that data back to a disk location first. Once on disk (you would see four BAK files in the example above) we initiate the request to Microsoft to restore the data from the BAK files that were laid down in the staging directory so that the four streams can be provided to satisfy the restore request.
thanks for your explanation, but the Restore Source is a Disk DashCopy.
We restore Fullbackups to the VMs we are replicating using LveSync. For the bigger SQL-Server the DB-Data/Log Disks are excluded during the VM-Backup, so we add the disks and folder to this VMs manually and use the original CV-Client to restore the Data.
Often the recovery process will cause the Job Results hard drive to fill up completely so we have to add an seperate Disk for that too.
If this option is enabled, even if the secondary copy you are restoring from is also disk, I believe the IDA still detects that Combine to Streams was used and attempts to rehydrate the data in the Job Results directory.
You can attempt to disable the staging of the data to the Job Results directory on the DESTINATION server using the setting below. This would allow the restore to attempt itself in the traditional fashion without staging the data, but it is important to note that depending on the configuration, (such as Tape, or where we aren’t able to provide SQL with the exact number of streams on restore as were taken on backup) the restore job might fail.