Hi !
I’m used to old-style storage/schedule policies and clients/subclients associations..
But we’re told that PLANS are the future, and we’ll have to move to Plans for sure.
So I’ve deployed a few new MAs to protect some locations inside my company, where I have to protect VSA + file level backups.
I have local disk backup, then auxcopy to tape and auxcopy to cloud from primary.
MA is physical linux, as we have windows VSA clients, I have also deployed Windows VSA Proxy.
Then I created Storage pools for local disk, tape copies and Cloud copies.
To simplify things and test Plans, I created a Plan per location, with standard details, like 1 day RPO, 1 month of retention, with my backup timeslots, full timeslots (confusing with synthfull out of control, but we’ll discuss that later in this thread I guess).
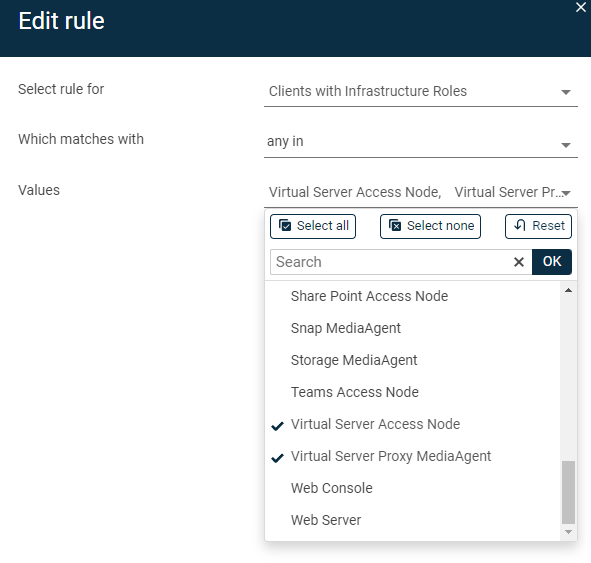
I created a VSA VM group that points to my VMWare location ( = selects all the VMs in that location, including my VSA proxy VM).
For some VMs, I was asked to also provide file-level backup of some key folders more often than the daily backup, so for this I later derived from this plan, keeping all setting but changing RPO to like 1 hour and retention to 2 days.
To make sure I would not get a non protected VM in the hypervisors overview, that’s how I did.
But the problem is that all backup jobs start at the same time, and the VSA Proxy VM itself is beeing backup while it is backing-up all the other VMs, causing warnings, or even potential issues.
I would like to know how you would do (or have done) in such case, as my target is to simplify/ease/automate as much as possible, reduce amount of formerly called StoragePolicies, and make sure any new VM created in a location is automatically included in the Plan.
I would find helpful to be able to provide some kind of priority in Plans, or override timing options in clients and subclients associated to a plan, instead of having to Derive from a plan just to provide other backup timeslots.
And while I’m writing about timeslots in plan, well, I find it a bit hard not to be able to manually input backup timeslots in Plans (clicks are sometimes approximative, I’m not good at mouse drawing..) and also select more precise times other that ‘oclock’ times, like 1:15AM or 23:35. Today so far it’s only 1:00AM or 23:00 or midnight. But nothing inbetween.
Mike or any moderator, don’t hesitate to move this conversation to what should be its more accurate location here 🙂