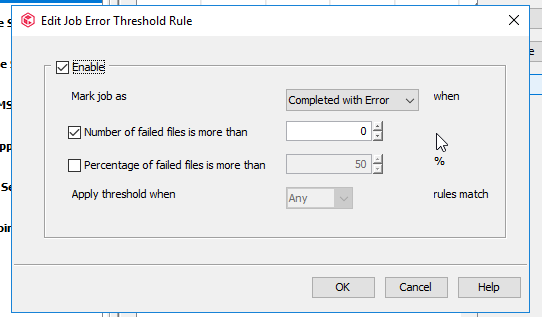
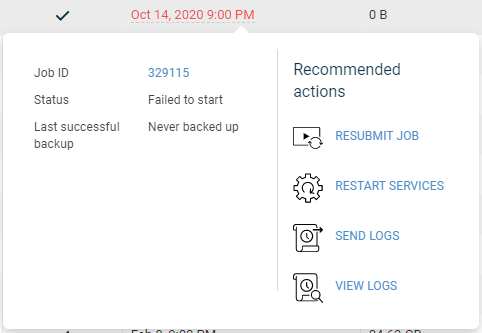
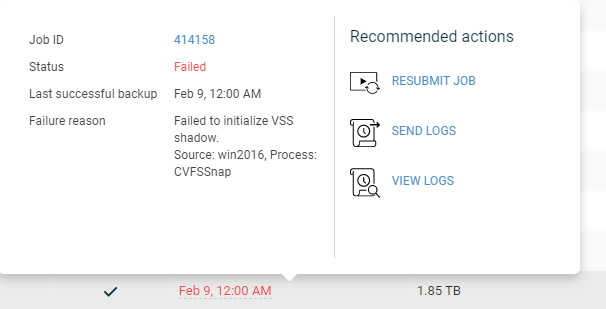
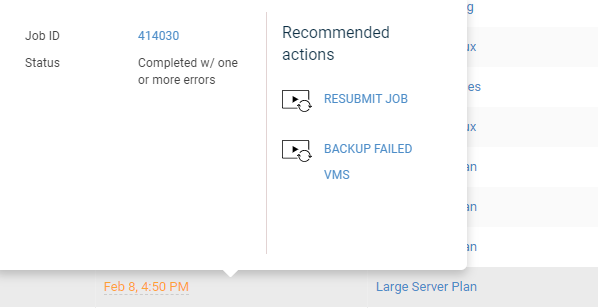
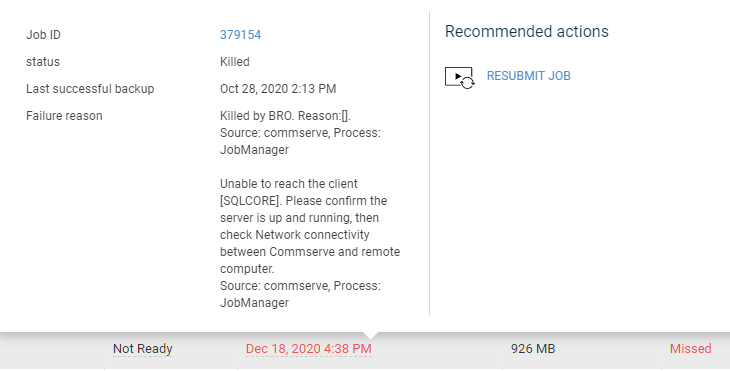
The file system backups are showing as successful(no warning) however failing to protect some of the files; I am wondering why the job is not completing with partial sucess and showing it as a VSS issue. Is that becuase there are no application specific vss writers for the application and hence quiesing is not working its magic
- [C:\Program Files (x86)\BigFix Enterprise\BES Client\__BESData\SiteData.db] The process cannot access the file because it is being used by another process.