Hi all!
could you advice me how to troubleshoot following types of error:
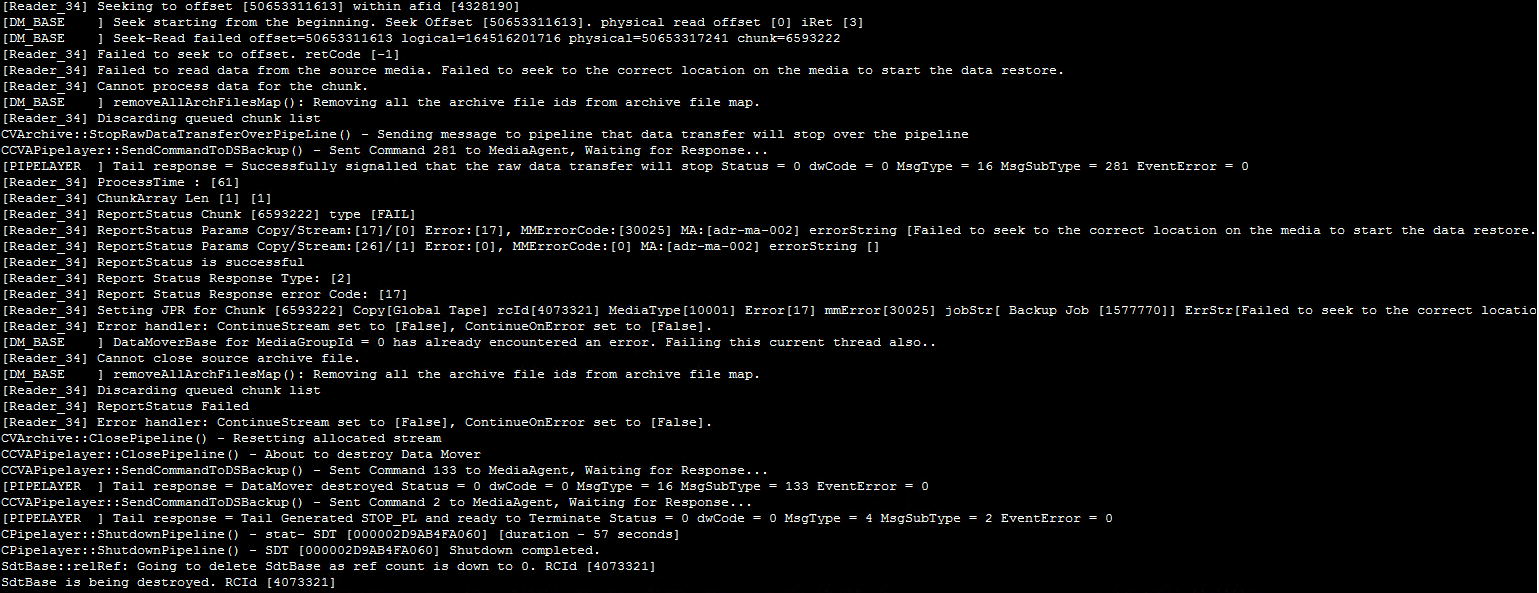
Error Code: [13:138] Description: Error occurred while processing chunk [xxx] in media [xxx], at the time of error in library [disklib01] and mount path [[xxx] /srv/commvault/disklib01/xxx], for storage policy [XXX] copy [Xxx] MediaAgent [svma1]: Backup Job [xxx]. Unable to setup the copy pipeline. Please check connectivity between Source MA [svma1] and Destination MA [svma1].
At a glance, it seems that it is not possible for CV to process chunk from the (index?)/disk library...However, the issue is connected with storage policy copy, that moves data from the disk library to the tape library (secondary copy). The main problem for us is that it is not possible to copy data to the tapes. Therefore, it may say Unable to setup the copy pipeline. The media agent is one server/device, that communicates with both disk and tape library. Lastly, the files in the related directories dont seem to be corrupted...
Any suggestions and ideas will be appreciated!