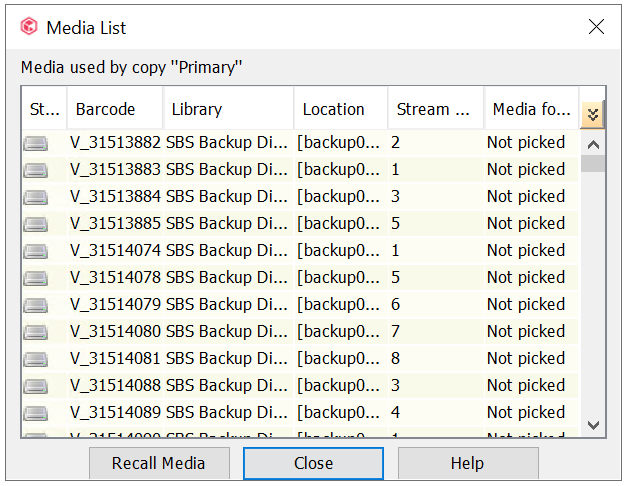
Commvault is showing 75 TB of data to be written to tape. We have set the tape copy to be “combine source data streams” to 3 (so it will use 3 tapes) and multiplexing is set to 5.
Additionally: We have the “Data Path configuration” set to use alternate Data paths when ‘resources are busy”, and (in the policy) checked “enable stream randomization...” and “distribute data evenly among multiple streams...”
Started the job, it chose to only write to 2 tapes, and also chose an alternate media agent to use (not sure why, the default media agent has 2 available tape drives and does not appear to be busy).
Looking at the job, it only used 7 readers BUT there is a single stream/entry for ‘media not copied”… it does not seem to have determined it needed to use 3 streams.. yet it has a single stream “waiting” … and its not writing “10 readers” (only 7)… so the reader counts/multiplexing seems to not be honored ( as there is a single stream waiting in ‘media not copied”.
why didn’t it break up the streams/multiplex so it would write to all the available tapes (3)? why is 1 stream configured to hang out and wait?
Also: the stream ‘waiting” is in “stream 2”. the tapes that are writing *does* have 5 readers for stream 2 so it might make sense for this waiting stream… BUT the other stream/tape only has 2 readers… why didn’t the streams all get assigned evenly so they could all write? It seems the system would have evenly allocated the streams/readers.
Best answer by Mike Struening
Yeah, I recall the same confusion when I started 15 years ago. Especially hearing people say streams when they mean data readers, etc.
Streams are the connections for the Storage Policy (before we get to Aux Copies and combining).
I like to refer to this section in the overview to clear things up (and yes, there are multiple ‘streams’ ):
The following concepts are important to understand before you configure device streams.
MediaAgent Level
You can set the maximum number of concurrent read/write operations on the MediaAgent by the Maximum number of parallel data transfer operations setting. This value controls the maximum number of data streams that can be managed by the MediaAgent.
Storage Policy data streams are logical channels that connect client data to the media where data that is secured by backup operations are stored. For a storage policy, the number of device streams that is configured must be equal to the number of drives or writers of all libraries that are defined in the storage policy copy. No benefit is gained if the number of device streams is greater than the total number of the resources that are available.
Disk Library Level
For disk library, the number of device streams is based on the total number of mount path writers for all mount paths in the library. For example, if you have a disk library with two mount paths that have five writers each, a total of ten device streams can be written to the library. When you increase the number of mount path writers, more job streams can be written to device streams.
Tape Library Level
For tape libraries, one sequential write operation can be performed to each drive. If there are eight drives in the library, then no more than eight device steams are used. By default, each data stream writes to a device stream. To allow multiple data stream to be written to a single tape drive, multiplexing can be enabled. This multiplexing factor is determined by how many data streams can be written to a single device stream. If a multiplexing factor is set to four, and there are eight drives, a total of thirty two data streams can be written to eight device streams.
How each one fits into the next will differ depending on the environment, though the options allow you to configure bottlenecks/limits as you want.
If you need further clarity on anything, update us here. I’ll keep it open for a while just in case!
If you have a question or comment, please create a topic
This is a great question, and something that illustrates how stream operate.
Without looking at the actual job you are seeing, I can describe how Primary, and Aux streams work (by default) and you can advise back if this describes what you are seeing.
The Primary Copy has a stream count (inherited from the Storage Policy itself). when Primary jobs run, they will seek out stream 1 by default, and write to it. If another job comes along, it will go to stream 2 (by default), and so on.
Now, depending on a few factors like data readers, if you are only running a few jobs at a time, then you will likely see only a few streams used. that’s because we don’t use more streams than asked. If 3 single streams jobs run at a time (and there’s never more than 3), then we will only see 3 streams used, ever (by default).
Once the Aux Copy runs, it will combine the streams (if enabled) into whatever number you select. If the Primary has 50 streams available, but we have never used more than 3, then combining to say, 5 streams, will do nothing additional since we only need 3.
Multiplexing allows us to write multiple jobs to single streams. Writing is REALLLLLLY fast while reading is REALLLLLLLY slow.
It works like this:
Normally, a series of jobs write to tape (or whatever media) sequentially). Jobs A, B, and C will write:
AAAABBBBCCCC
and during this time, each job/client has to sit and wait its turn.
but with multiplexing, these 3 jobs share a stream and write as they are ready so you get:
ABBACABCC (or whatever random allotment)
You can see, this is much faster for the backup phase, but imagine having to rewind and re-read a tape to get all of the pieces of job A? And the example above is VERY simplified.
So, with all of that said, how many streams is the Primary set to use maximum? How many has it used for the existing jobs?
Is multiplexing and randomization enabled across all copies, or just 1?
there’s likely nothing wrong but we definitely want to see why things are working as they are!
Q1: ”...how many streams is the Primary set to use maximum?
A1: I’m not sure actually, this policy is used for backing up a lot of file shares (looks like around 30), and I believe most/all of them are set to 2 readers (the default, but i don’t know how to easily check them all). The primary copy itself has no readers I can see/set, but at the policy level I see its set for 150 device streams. Multiplexing at the primary copy is not set, as we are using deduplication.
Q2: “How many has it used for the existing jobs?”
A2: I’m not sure and don’t know where to look for this. I’ve been rebalancing tape jobs/multiplexing/scheduling to try to increate throughput and I thought that I had it all figured out . This is the first one that has surprised me on how has been running (with these specific stream behaviors)
Q3:Is multiplexing and randomization enabled across all copies, or just 1?
A3: multiplexing and randomization is set at the policy level.
primary copy: no multiplexing, deduplication enabled
secondary/aux copy (pulls from primary copy): combine streams set to 8, no multiplexing
tape copy (pulls from secondary/aux copy): combine streams set to 3, multiplexing to 5
Adding to this: So, it looks like *possibly* I’m never really using a lot of primary streams…but the schedule for all the NAS copies runs all at the same time so I’d imagine it would use more streams on the primary? I haven’t watched how many streams run on the secondary (it runs at night) so see if its using 8 or just 2, but i would imagine it would be using more than 2 since all the NAS primary backups run all at the same time (and they all likely have 2 streams configured)
So based on your answers (thanks, again) I think the likely answer here is that you have not used all 150 streams (unless you have that many incoming streams simultaneously, it’s not likely).
Right-click the Primary copy and select View Media. It should show you the various streams in use.
Check this for some contextual info on active streams:
I see a lot of tapes listed, and its showing some have ‘stream 3” in it, but no dates on teh tapes/streams so I’m not sure what tapes were part of this last run. Maybe for some reason it just decided not to use 3 tapes that time? The tape job has completed… is there anything in the job logs to look for to see what the “logic” is for choosing tapes/streams/multiplexing? If not, no biggie I was just trying to understand hoy it was working differently than my expectations when I manually ran the tape job
I have a question about what you wrote above about the “streams” and how streams are used within a “primary → Aux copy (secondary) → tapes” framework. Sorry but I’ve been thinking :)
Lets assume I have a storage policy, and the primary copy runs a single job per day (lets say its backing up a single filesystem subclient. Lets say this subclient is configured for 2 readers and they are all used ( its a 100 TB filesystem… large for this example, but maybe not optimized for readers :))
So the primary copy runs using both readers (streams). Then the Aux copy is set up to run and it is set for 3 streams (no multiplex because we’re using a DDB, and I guess multiplex is not allowed when a DDB is being used).
Question: The aux copy runs and I suspect (from what you said) is will/can only use 2 streams, because there were only 2 streams of “data” available?
IF true there are only 2 streams...
So: 30 days pass, every day that primary job uses 2 streams...
When tapes run, it pulls “the last full backup of the month”, and the tape job is set to 3 streams, 5 multiplex”.
Question: How many tapes would write ( I suspect 2, as there are only 2 streams and it would pick 1 stream per tape...), but would the multiplex not do anything? or would it just write 1 tape and only be able to use 2 streams for the multiplexing on it?
Follow up question: IF the stream counts used on the primary can be the “bottleneck” for running aux copies and tapes (especially if you have a very low number of streams available, because the example I gave is a single job/subclient), can you increase throughput of the “large TB’s of data” by adding readers to the primary copy (assuming you can add more, possibly by breaking up what the subclient backs up into multiple subclients) or is there another way to increase throughput (without adding hardware/cpu’s)? I believe having “more large subclients, all tied to the same storage policy” would help because the big chunks woudl all be running together( assuming the stream randomization and stuff is working properly?), but I’m wondering about the granularity at the single subclient level, assuming I have just 1 subclient with a huge amount of data. Like, can I break up a 100 TB “backup job” by simply adding more readers on the primary copy so the “chunks” of data being processed will be smaller as it gets aux copied/put onto tape? I ask this because we have some large “chunks” of data on the streams that are always ‘the last stream running” and the throughput of the aux/tape job goes waaaay down just chewing on that single stream of like 10-20 TB. I believe these large chunks are from filesytem clients ( doing NAS backups) , a few servers with lots of data on the C;\, D:\ drives, and our VM backups (lots of servers per subclient in a backup, doing incrementals/synthetic fulls). I’m a little unsure if there's a better approach to breaking up the larger stream “chunk size” smaller so the Aux copies and tapes don’t have 20 multiplex stream running (It’s running GREAT!”) , then in 4 hours finish 19 of them and just chew on that 1 big 20 TB stream for days (“its running terribly!), because for some reason it didn’t get broken up into 10 “2 TB” streams.
I see a lot of tapes listed, and its showing some have ‘stream 3” in it, but no dates on teh tapes/streams so I’m not sure what tapes were part of this last run. Maybe for some reason it just decided not to use 3 tapes that time? The tape job has completed… is there anything in the job logs to look for to see what the “logic” is for choosing tapes/streams/multiplexing? If not, no biggie I was just trying to understand hoy it was working differently than my expectations when I manually ran the tape job
CVMA.log or MediaManager.log might show that detail, though likely not without a higher debug level.
However, you have the answer. You DO have 3 stream tapes, but whether or not the current running Aux Copy needs all 3 is dependent on the job’s needs at that time.
I have a question about what you wrote above about the “streams” and how streams are used within a “primary → Aux copy (secondary) → tapes” framework. Sorry but I’ve been thinking :)
Lets assume I have a storage policy, and the primary copy runs a single job per day (lets say its backing up a single filesystem subclient. Lets say this subclient is configured for 2 readers and they are all used ( its a 100 TB filesystem… large for this example, but maybe not optimized for readers :))
So the primary copy runs using both readers (streams). Then the Aux copy is set up to run and it is set for 3 streams (no multiplex because we’re using a DDB, and I guess multiplex is not allowed when a DDB is being used).
Question: The aux copy runs and I suspect (from what you said) is will/can only use 2 streams, because there were only 2 streams of “data” available?
IF true there are only 2 streams...
So: 30 days pass, every day that primary job uses 2 streams...
When tapes run, it pulls “the last full backup of the month”, and the tape job is set to 3 streams, 5 multiplex”.
Question: How many tapes would write ( I suspect 2, as there are only 2 streams and it would pick 1 stream per tape...), but would the multiplex not do anything? or would it just write 1 tape and only be able to use 2 streams for the multiplexing on it?
Follow up question: IF the stream counts used on the primary can be the “bottleneck” for running aux copies and tapes (especially if you have a very low number of streams available, because the example I gave is a single job/subclient), can you increase throughput of the “large TB’s of data” by adding readers to the primary copy (assuming you can add more, possibly by breaking up what the subclient backs up into multiple subclients) or is there another way to increase throughput (without adding hardware/cpu’s)? I believe having “more large subclients, all tied to the same storage policy” would help because the big chunks woudl all be running together( assuming the stream randomization and stuff is working properly?), but I’m wondering about the granularity at the single subclient level, assuming I have just 1 subclient with a huge amount of data. Like, can I break up a 100 TB “backup job” by simply adding more readers on the primary copy so the “chunks” of data being processed will be smaller as it gets aux copied/put onto tape? I ask this because we have some large “chunks” of data on the streams that are always ‘the last stream running” and the throughput of the aux/tape job goes waaaay down just chewing on that single stream of like 10-20 TB. I believe these large chunks are from filesytem clients ( doing NAS backups) , a few servers with lots of data on the C;\, D:\ drives, and our VM backups (lots of servers per subclient in a backup, doing incrementals/synthetic fulls). I’m a little unsure if there's a better approach to breaking up the larger stream “chunk size” smaller so the Aux copies and tapes don’t have 20 multiplex stream running (It’s running GREAT!”) , then in 4 hours finish 19 of them and just chew on that 1 big 20 TB stream for days (“its running terribly!), because for some reason it didn’t get broken up into 10 “2 TB” streams.
Bonus questions are good!
the first question is simpler, you are correct. If you have a 2 stream Primary, combining to 3 streams is extraneous. Now, multiplexing will likely put both streams on tape 1 and be the end, so keep that in mind.
Regarding the second question….you are asking all the right questions. It’s pretty complex (in a good way), though the best way to look at it (at least to start) is about spindles/resources. There’s no point in breaking the c: drive into more subclients to gain performance boosts unless the actual hardware can handle the same throughput simultaneously/ Conversely, if your source data is set up as a LUN or SAN drive, then resources can be allocated as needed and your subclients can all zip along together. In the older days of physical HDDs we would recommend subclients per drive since the actual server could handle the throughput and each drive could act independently. These days, there are so many ways and places data can be stored (for source data) that it depends, but we give you a LOT of control (the good part of complex) on how the data is read, how it is backed up, how the secondary copies are sent, etc.
there’s a REALLY cool guide on streams here that covers pretty much everything. There’s a lot to see, but the doc breaks it down nicely:
Thank you for the info! I’ve read the link but I’ll need to go over it again as its been awhile and this new information will help puzzle it out.
I think the mental block I have been having is the concept of a “stream” (to me, normally, in the world outside of commvault) is like process (with a PID, not like a workflow)...err literal script/code to open filehandles to read/write a file (an iostream, a pipe, etc.). and process data, then some other script can read the result data and and do whatever it wants to with it, but in commvault the stream’s “data” has a level of persistence/immutability as they (the streams) move through the system from primary → aux copy → tape because the data associated with the primary streams cannot be broken up by other processes/streams. Meaning: a stream is basically like a normal “open pipe/filehandle/reader etc.” when it starts on the primary (as “readers”) but then the data that was read/backed up… blocks/chunks/whatever it gets turned into, maybe some special format... that get written are then considered “the stream data” or ‘the data associated with a stream” or “the black box of data that shall be immutable” and don’t/can’t get broken up by subsequent copy/reader/stream operations. As if when secondary/aux copies handles the data, it can only see those “chunks” and the aux copy “streams” (actual processes/readers of the “stream” data block) can only read/migrate/copy that chunk “as a single unit” and cannot decide to fragment it into smaller/arbitrary/more manageable chunks and thus handle it with more streams if needed. As an aux/tape copy handles those “single units” it allocates 1 stream per unit ( and will never allocate 1 aux copy stream to handle 2 or more small “units” or “streams” from a primary copy… its always a 1 to 1 relationship of primary stream “written data chunk” to aux/secondary/tape streams ‘reading that same data”). Multiplexing is then just a way to … err… bundle a bunch of streams/blocks under a “main stream” to gain performance in certain situations (as you have mentioned) and not some way of breaking up the underlying streams data into easier manageable chunks.
I guess maybe another way of looking at is it a stream is ‘its the data written to disk’ and not the “process/thread reading/writing the data”, even though the terms/concepts are kinda used interchangeably at times. Kinda like how a “service”.. can be a lot of similar but different things under the hood..
I’m being a little repetitive here and beating this to death (and just trying to clarify my thoughts in case I’m way off on something), but this is starting to make more sense now. Thanks!
Yeah, I recall the same confusion when I started 15 years ago. Especially hearing people say streams when they mean data readers, etc.
Streams are the connections for the Storage Policy (before we get to Aux Copies and combining).
I like to refer to this section in the overview to clear things up (and yes, there are multiple ‘streams’ ):
The following concepts are important to understand before you configure device streams.
MediaAgent Level
You can set the maximum number of concurrent read/write operations on the MediaAgent by the Maximum number of parallel data transfer operations setting. This value controls the maximum number of data streams that can be managed by the MediaAgent.
Storage Policy data streams are logical channels that connect client data to the media where data that is secured by backup operations are stored. For a storage policy, the number of device streams that is configured must be equal to the number of drives or writers of all libraries that are defined in the storage policy copy. No benefit is gained if the number of device streams is greater than the total number of the resources that are available.
Disk Library Level
For disk library, the number of device streams is based on the total number of mount path writers for all mount paths in the library. For example, if you have a disk library with two mount paths that have five writers each, a total of ten device streams can be written to the library. When you increase the number of mount path writers, more job streams can be written to device streams.
Tape Library Level
For tape libraries, one sequential write operation can be performed to each drive. If there are eight drives in the library, then no more than eight device steams are used. By default, each data stream writes to a device stream. To allow multiple data stream to be written to a single tape drive, multiplexing can be enabled. This multiplexing factor is determined by how many data streams can be written to a single device stream. If a multiplexing factor is set to four, and there are eight drives, a total of thirty two data streams can be written to eight device streams.
How each one fits into the next will differ depending on the environment, though the options allow you to configure bottlenecks/limits as you want.
If you need further clarity on anything, update us here. I’ll keep it open for a while just in case!





 . This is the first one that has surprised me on how has been running (with these specific stream behaviors)
. This is the first one that has surprised me on how has been running (with these specific stream behaviors)