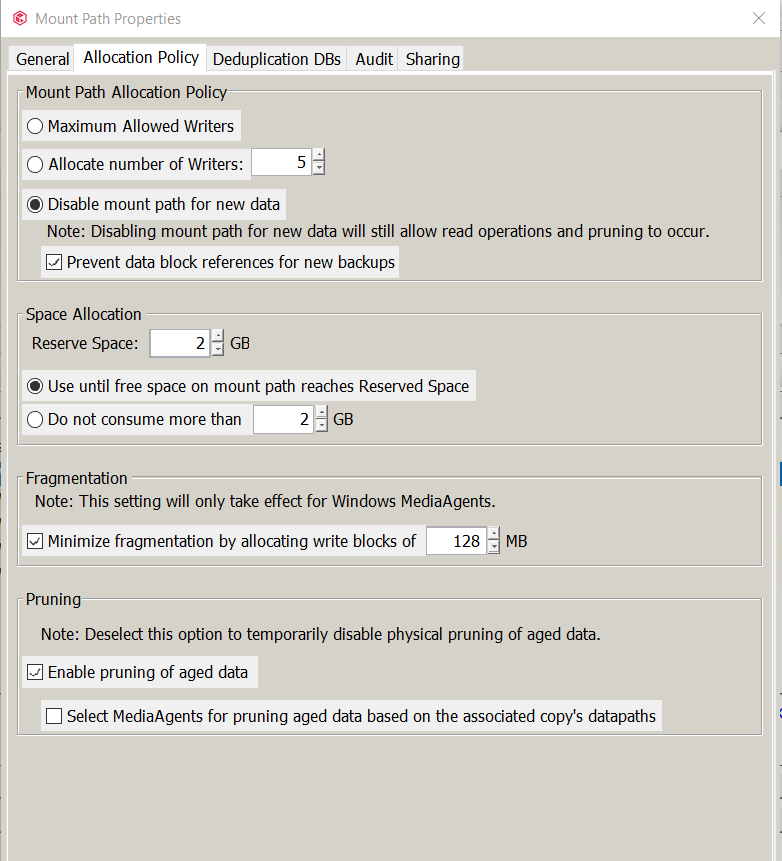
We have added new storage to Commvault, and set the old mount paths to “Disabled for Write” via the mount path “Allocation Policy” → “Disable mount path for new data” + “prevent data block references for new backups”
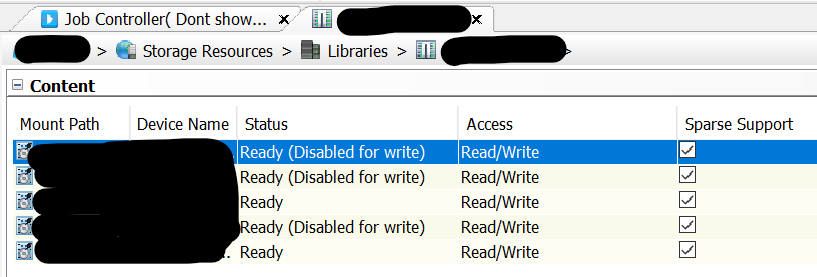
All mount paths that are “disabled for write” do not have any data on them via the “mount path” → “view contents” option.
We have waited a several months for all the data to age off.
BUT…
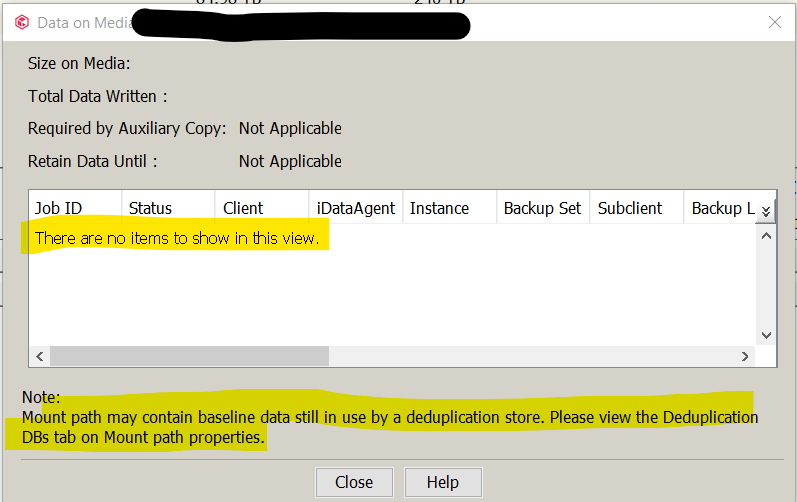
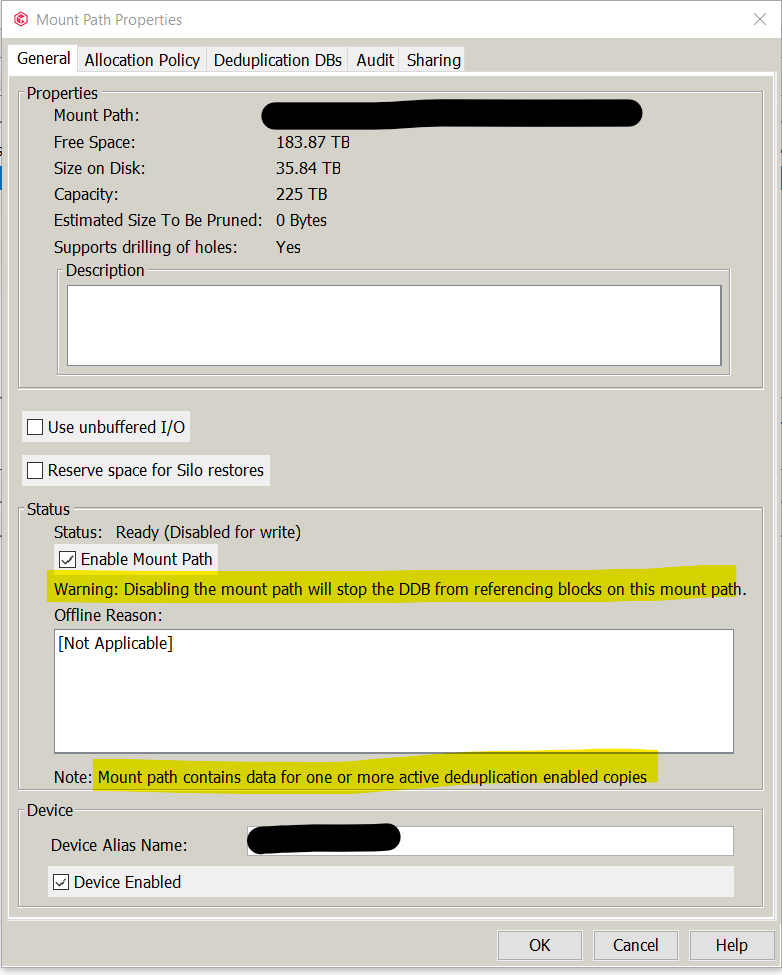
I see info on the forums/docs that “data’ may still be on the storage, and there are referenced to “baseline data” in use by our DDB’s. When I go to the mount path properties → Deduplication DB’s tab, I see that all our “disabled for write” mount paths have DDB’s listed in them. So it appears commvault is still using the storage in some way. I saw a post that indicated “The LOGICAL jobs no longer exist on that mount path, but the original blocks are still there, and are being referenced by newer jobs. For that reason, jobs listed in other mount paths are referencing blocks in this mount path as well.”
Also: When going on the servers and looking into the mount paths, there are *many* folders in the CV_MAGENTIC folder, some going back as far as 2017 for their modified time. This would make sense if CommVault were still referencing data on the disks…. but 2017 seems a bit extreme
I’m a little unsure how to proceed to make sure that I can cleanly delete/remove these mount points and was looking for any advice/procedure/protocol to properly clean them up so we can cleanly delete them.
I see some references to “retiring” a mount path in Performing a Space Reclamation Operation on Deduplicated Data (commvault.com), and removing orphan data… then “disabling it” https://documentation.commvault.com/11.24/expert/9367_enabling_disabling_mount_path.html and then finally deleting it (with or without backup data… I’m not sure what I fall under) https://documentation.commvault.com/11.24/expert/129498_deleting_mount_path_without_backup_data.html
but I’m not sure if there are any other considerations to do/try or if this “is it”. This appears to be connected to the “System Created DDB Space Reclamation schedule policy” and for our system this is not turned on (not sure if this is recommended/default/etc.)
Also: I’ve seen some references to “run the data retention forecast and compliance” report to see what is being referenced, but I’m not sure how to run this so it will only show me what data may be left (vs running it for “everything” and then sifting through a massive report, line by line). No jobs are referencing it when viewing “mount path” → Contents.
Also: We had issues for a long time on this storage array with folders/chunks that were corrupt, so I’m reasonably sure that Commvault will not be able to delete all of these remaining folders on disk if it tried to clean them up, but I’m not sure how many are left that might be corrupt. spot checking (opening them up) yielded none that were unopenable/corrupt at the OS/filesystem level. I bring it up as I’m not sure what happens if any of the above procedures attempt to run and cannot delete/remove a file/folder.