How to properly deleting/decommissioning mount points associated to old storage: DDB's appear still associated with the mount paths.
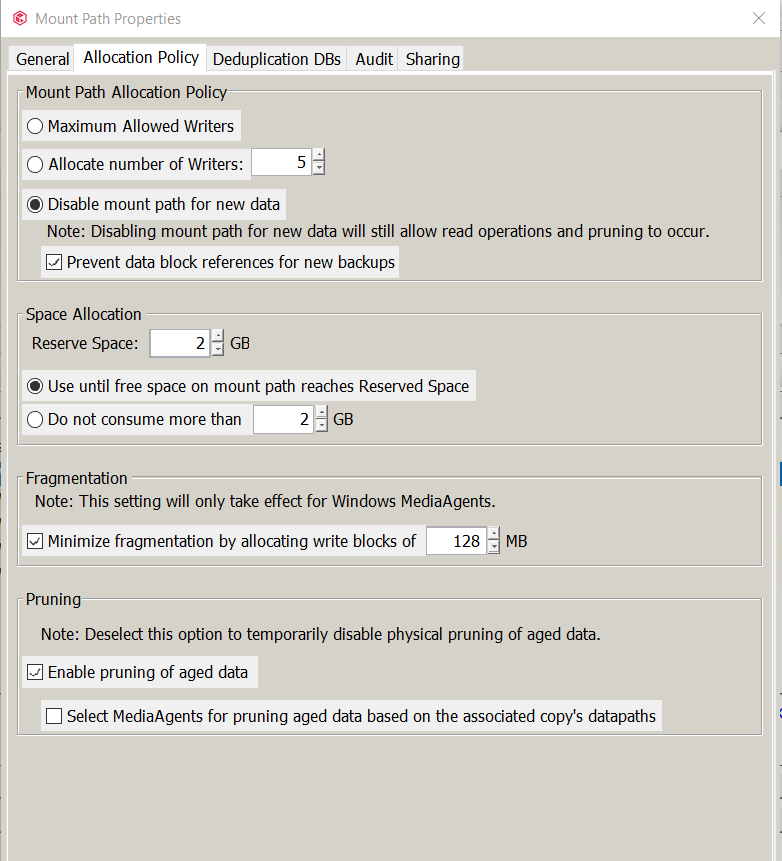
We have added new storage to Commvault, and set the old mount paths to “Disabled for Write” via the mount path “Allocation Policy” → “Disable mount path for new data” + “prevent data block references for new backups”
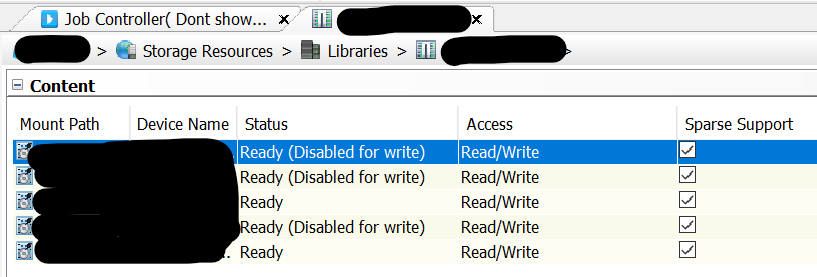
All mount paths that are “disabled for write” do not have any data on them via the “mount path” → “view contents” option.
We have waited a several months for all the data to age off.
BUT…
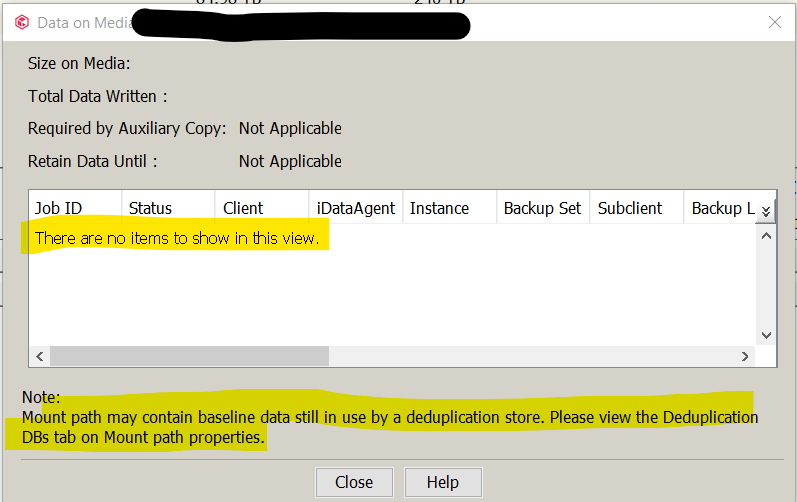
I see info on the forums/docs that “data’ may still be on the storage, and there are referenced to “baseline data” in use by our DDB’s. When I go to the mount path properties → Deduplication DB’s tab, I see that all our “disabled for write” mount paths have DDB’s listed in them. So it appears commvault is still using the storage in some way. I saw a post that indicated “The LOGICAL jobs no longer exist on that mount path, but the original blocks are still there, and are being referenced by newer jobs. For that reason, jobs listed in other mount paths are referencing blocks in this mount path as well.”
Also: When going on the servers and looking into the mount paths, there are *many* folders in the CV_MAGENTIC folder, some going back as far as 2017 for their modified time. This would make sense if CommVault were still referencing data on the disks…. but 2017 seems a bit extreme
I’m a little unsure how to proceed to make sure that I can cleanly delete/remove these mount points and was looking for any advice/procedure/protocol to properly clean them up so we can cleanly delete them.
but I’m not sure if there are any other considerations to do/try or if this “is it”. This appears to be connected to the “System Created DDB Space Reclamation schedule policy” and for our system this is not turned on (not sure if this is recommended/default/etc.)
Also: I’ve seen some references to “run the data retention forecast and compliance” report to see what is being referenced, but I’m not sure how to run this so it will only show me what data may be left (vs running it for “everything” and then sifting through a massive report, line by line). No jobs are referencing it when viewing “mount path” → Contents.
Also: We had issues for a long time on this storage array with folders/chunks that were corrupt, so I’m reasonably sure that Commvault will not be able to delete all of these remaining folders on disk if it tried to clean them up, but I’m not sure how many are left that might be corrupt. spot checking (opening them up) yielded none that were unopenable/corrupt at the OS/filesystem level. I bring it up as I’m not sure what happens if any of the above procedures attempt to run and cannot delete/remove a file/folder.
Page 1 / 1
Good morning. If the mount path in question is associated to a DDB that is holding baseline data, then even though that mount path shows no jobs, there could be baseline data on the mount path. As of FR21, you can delete a mount path with data on it as shown here:
Keep in mind that this will corrupt the DDB associated if in fact there was baseline data on the mount path. You will need to run a full DDB verification after in order to identify jobs that were deleted and mark them bad so they are no longer referenced.
I saw that document, and I have several questions about it. I’m sorry for all the questions, and if its a bit too much I can open a support ticket!
At the beginning it states: “If you shared the mount path with a MediaAgent that is online with write access and with Feature Release 21 or later version, then the delete operation deletes the mount path along with data from the CommServe database and the physical storage. Otherwise, the delete operation only deletes the mount path from the CommServe database”
We have set the mount paths to ‘Ready, Disabled for Write” for months (to allow content to be cleared out on its own/aging), so it sounds like the delete is only going to delete the path from the Commserve DB (option 2 above)? this means to me it's not going to clean up the storage (which is fine, but i was hoping it would be “empty” and thus “we know CommVault is no longer using it” when we decommed the storage). So we should be presented with the “Force delete mount path” option.
In the “Before you begin” section, it basically says “make sure the paths you’re deleting are not in use”… well, we have them set to “read only” , and I guess if there’s TB’s of data being referenced on them (I assume its being used, as its not deleted?), that qualifies as ‘in use”. we have Aux copies running frequently (2x daily)… so to me this means we’ll have to deschedule/shut down all Aux copy operations as we don’t know how long this is going to run?
There’s a blurb for “If the mount paths are silo enabled...”, which I’m guessing translates to the setting “Reserve space for silo restores”? We don’t have this setting enabled, so it appears we don’t have to do all the steps for silo enabled, meaning sealing the DDB’s, ageing jobs, etc.?
What concerns me most is the “... this will corrupt the DDB associated if in fact there was baseline data on the mount path. You will need to run a full DDB verification after in order to identify jobs that were deleted and mark them bad so they are no longer referenced.”
We have ~80 TB of this “baseline data” (based on adding up the “size on Disk” on all the mount paths we would be deleting. I’m a little concerned what jobs we would have to be deleting, how large of a “hole” this would leave, etc. in our backups. if there any way to “see” these jobs before deleting the mount paths, or some way of cleaning up or migrating this “Baseline data” to the new storage without doing a force delete of the mount points and finding out how bad it will be after the fact?
Hello @tigger2
Commvault needs Write permissions to be able to Prune. Can you enable Writes, but leave them disabled for new data? Run data aging and the data should prune off.
Thank you, Collin
I’m not sure how to enable writing without the current backup jobs NOT write any data to the mounts. Support had us set it to ‘read only” when we set up our new storage so it would not use this old storage/mount points for new backups. Here’s some of the settings we have on the mount paths:
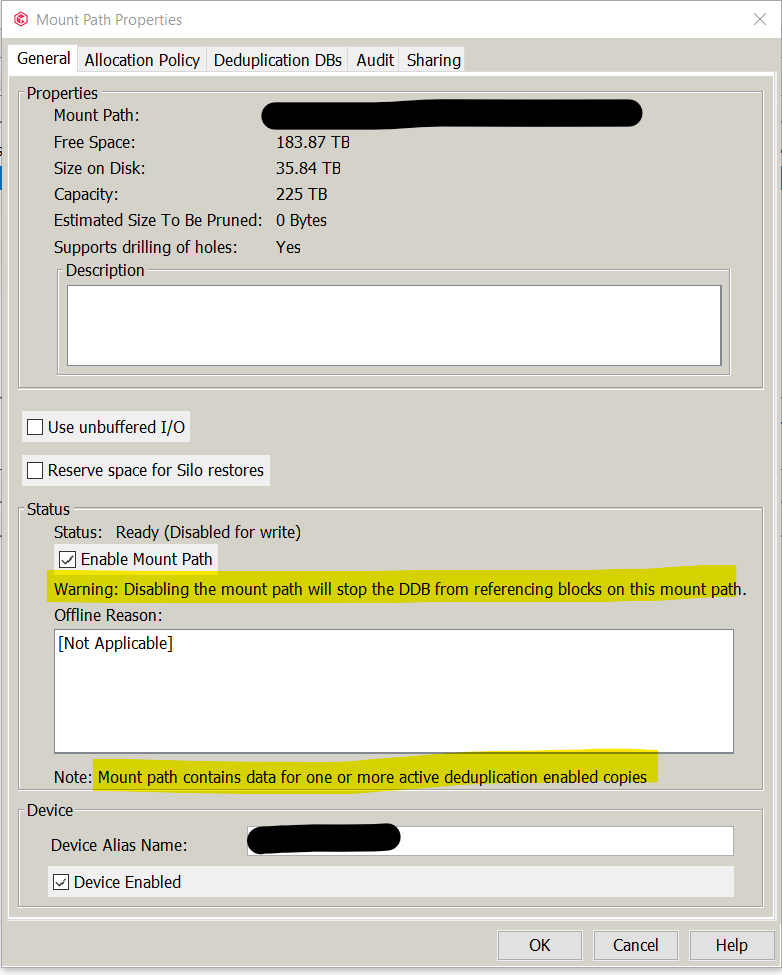
Mount path properties, then mount paths (showing “disabled for write:), then mount path → view contents (showing they are empty, but ‘DDB may be referenced), then mount path properties (showing 35 TB of data on disk, and DDB’s are being referenced…
the last pic makes me think “disabling” the mount path will cause the DDB’s to cleanup…and may be the next step before deleting/retiring them ? If so, will this be when data verification runs?
Hello @tigger2
That looks correct. I must have misunderstood. It might be worth it tog get a Support case open, but do you see any errors in CVMA.log or SIDBPrune.log on those MediaAgents?
Also, if you have access to SQL, you can use the below query to see if any records are up for logical pruning for the associated DDB. There is a column in the results for fFailureErrorCode] indicating a pruning error. If there is, let me know the error code and I can look up the reason.
Use CommServ
Select * from MMDeletedAF where SIDBStoreID = <insert relevant DDB ID here>
Thank you, Collin
Following this thread with interest - I retired a couple of mount points and there’s no jobs remaining on the mount points but there is still 20-30GB of “baseline” data that Support said would clean-up at some point.
The data hasn’t yet, my workaround was to do a mount path move to relocate the data to another location so I could repurpose the disk.
The current status of them is they are disabled for write but still enabled as per @tigger2’s last screenshot.
I don’t have access to run SQL (I’ll have to request SQL Mgmt studio and get approval if I do) and there appear to be no errors in the CVMA.log, but the SIDBPrune.log does have errors, though these are expected as we had some filesystem level corruption on this old storage array, so some chunks are unopenable at the OS level (manually opening results in ‘this folder/file” is corrupt”). Its looks like this in the SIDB Prune log, for several chunks. We know some of these are just going to be this way, and it appears to be a minority (well, just spot checking) of the remaining chunk folders/files).
Additionally: I have a support ticket opened and we discussed a path forward for our system.
Essentially:
1. Perform full DDB Verification on all DDB’s
then see if we need or can to move the Mount points to the new storage.
then see if we need to Force delete anything (and Perform full DDB Verification, as apparently, we can do this on v11 SP24 and don't require DDB sealing but I could be wrong that this is the only reason)
Anyway: When we get it all done, I’ll update here with any anomalies/gotchas/etc.
Update: We have chosen a slightly different route
The DDB verifications took a long time (18 days, about), and 1 “completed with errors” very likely due to the corrupted data chunks on storage (which makes sense for what we observed).
We are allocating more space on our new storage to handle all the new chunks to be written to the new storage as a result of the plan of sealing all our DDB’s. Then we’re going to seal all our DDB’s and let it all “age off and clean up” naturally, if we can, which might take a month or so (hopefully). I believe if the chunks do not age off (with the sealed DDB) , then when the sealed DDB’s “age off and self delete” we’ll know “we’re done” and can just delete whatever data is on the old storage as it wasn’t referenced by anything (apparently). If our some of old storage has issues (blows up, etc) while we do this then we’ll just force delete whatever mounts are needed and decom/remove the storage/mounts in commvault of the affected storage, and deal with whatever issues we have.
Apparently, there is not a report or way to easily see all the “DDB referenced data/data references” associated with our DDB’s and the old storage (so it would be easy to say ‘ah, it's all not referenced but xyz jobs, nobody cares about them so let's just force delete and go have some cake”), but all the DDB verifications we did were basically ‘clean” except the one so it's not obvious what is being referenced. We have about 120 TB of “referenced data” on one of the old storage arrays that refuses to clean up, so moving it “to be safe” might just take a long time, may fail (becuse corruption) and it may never clean itself up (like random unconnected/forgotten chunks or something… I’m making this part up, but I can imagine it as the referenced data is not cleaning itself up by now...but maybe some would?) so might as well Seal DDB’s and get a fresh start. If we had less storage available to allocate then this might have been the preferred path, vs “delete and hope for the best and find out what jobs were hurt later” if we had no more storage to allocate at all.
Anyway, I’ll update again if anything interesting happens, else “it worked”
Update: since its been 30 days since last update:
We have escalated a case to development to determine why we are unable to move some data paths that have known OS/Filesystem level data corruption on them (like, why will Commvault will not skip these chunks, or why does data verification not mark them as bad and remove from the DDB, etc). So these are in a “waiting state” and are not cleaning up about 1 TB total data until we the ticket is worked. On our secondary storage, there has been “no auto cleanup” of the data still, even though our retention is just a month or a few weeks and this stuff is from mid last year when we cut off those mount paths from being ‘new data”…. so tons of ‘referenced data”. I’m trying to find places in commvault that might be holding this data (as a last backup, etc) but its a lot of data (80 TB still) so I doubt I’ll find that much. Ultimately these mount points may just have to be moved to the new storage as-is, and then maybe sealing DDB later or something as we’re pressed for time. we need to get off of the “old” storage very soon as time is running out, and I was hoping to get the data tobe moved shrunk down to make the migrations smoother/faster and less load on the system when it happens.
Its quite annoying to not be able to look into the “referenced data” to see what’s being used or what storage policies or clients its tied to or anything (other than the top level policy as linked to a DDB). If I know this “for sure” (like it was all references for old dev/sandbox backups … ha) it might make just deleting the mount paths (the very small ones, that have just a few hundred MB in them) more feasible, or at least be able to grasp “what's in there”. in theory it shouls be ‘all good, normal needed current data… but it coudl also just be data that’s left behind?). I think ultimately even after moving the mount paths, we might do a ‘sealing” exercise of each DDB, slowly one by onewhen we have time to just clean things up, if we have space on our new storage, as some DDB’s are big and have a lot of data referenced and “waiting around for references to clean up” (and DDB shrinking, eventual clean up/deletion) seems to be a “cross fingers and wait and see. maybe its fast, maybe its never. you’ll never know what is holding it up” when it just turns into referenced data
Final Update (for me): The solution was to install a special Diagnostic update (provided by support) which allowed us to migrate the mount paths and ignore/skip over the corrupted chunks on the old storage (with some manual work involved). This allowed us to get the data (the mount paths) we could migrated off of the old storage. Then we ran a Full DDB verification to clean up the DDB’s associated with the mount paths (there was only 1) that we moved to clean up the DDB itself from referencing any of the corrupt chunks we did not migrate (and to find any jobs affected, which require manual deleting)
This got us off the old storage, which was the main concern/goal.
The secondary concern is no longer a concern, but “how to clean up the “read only” mount paths so all data ages out/is no longer referenced” doesn’t appear to be something you can do without a sealing of the referenced DDB’s (in the mount paths), and that still will require the old sealed DDB to self clean up over time (and finally self delete). We may eventually do this at some point to clean up these “read only” mount paths, but time to do this and storage space is a concern at the moment. “upgrading commvault” is more of a priority right now… but this hopefully might help anyone who has this issue in the future.
I lied: this is the final update: I noticed that after successfully moving the mount paths and decommissioning my old storage, there were some “inaccessible” mount paths for each media agent for the moved mount paths: Seen under Storage Resources → Media Agents → emedia agent name] → tstorage array name ] → right click properties of the new moved mount path → go to “Sharing” tab”. The “local drive” teh path was moved to is ‘accessible” and teh “other paths” that are shared? via other media agents were “inaccessible”. The paths was shown as:
click on the inaccessible path → hit “edit” and update the path to the correct one ( make sure its the correct one!).
Support indicated that the path “accessible” info was updated a few times per day ( some schedule I forgot) so it would take a bit to show ‘accessible”