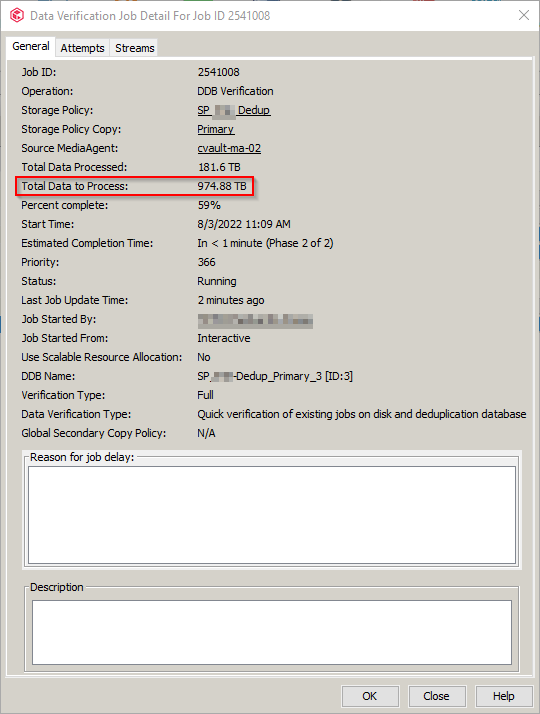
I started a quick (Full) DDB Verification Job to determine how much space can be recovered with DDB Space Reclamation and I am wondering if the Total Data to Process is somewhat equivalent to Back-end size. Is it right? I'm re-reading the guide “Deduplication Building Block Guide” and planning some changes. Maybe adding more nodes. One more question regarding Back-end size (for Disk Storage). In the context of “Deduplication Building Block Guide”, Is “DDB Disk” a partition?
If yes, so a setup with “4 Node with 2 DDB Disk per node” = 4 servers with Media Agent software installed with 2 partitions each one?
Best answer by Jos Meijer
The quick full verification will:
Quote:
“This option validates if the existing backup jobs are valid for restores and can be copied during Auxiliary Copy operations.
In comparison with the Verification of existing jobs on disk and deduplication database option, this option is faster because it does not read the data blocks on the disk. Instead, it ensures that both the DDB and disk are in sync.”
Space reclamation by hole drilling should normally occur automatically in the data aging process if the storage has sparse file support enabled. If hole drilling is not available the complete data chunks will only be aged when not referenced anymore by the DDB. Data aging is by default performed automatically on a daily base. To initiate reclamation manually for storage without sparse file support you can perform the space reclamation process. Advice is to consult support before using this.
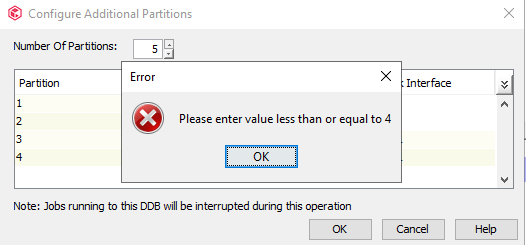
Quote: "To define the maximum number of allowed DDB partitions, set the Maximum allowed substore configuration parameter to 6. For more information, see Media Management Configuration: Deduplication"
In your example to use 4 nodes it would be logical to divide 4 partitions for 1 DDB over the nodes. So 1 partition per node. You can of course define 6 partitions in total and assign 2 remaining partitions on 2 nodes, but then load will not be balanced evenly over the nodes as 2 nodes will have 1 partition and 2 nodes will have 2 partitions.
Please note that load initially will not be evenly over the nodes as the existing partitions for a DDB already have references to blocks. This cannot be rebalanced to new partitions. Over time it can balance as references are aged in the DDB when the blocks referenced to are aged, but when this is achieved depends on the environment specifics.
A media agent can host multiple DDB's so in this context there would generally be a disk per partition belonging to a DDB. So if your MA is hosting 2 DDB's it can have for example 2 disks (one partition per DDB) or 4 disks (2 partitions per DDB)
“This option validates if the existing backup jobs are valid for restores and can be copied during Auxiliary Copy operations.
In comparison with the Verification of existing jobs on disk and deduplication database option, this option is faster because it does not read the data blocks on the disk. Instead, it ensures that both the DDB and disk are in sync.”
Space reclamation by hole drilling should normally occur automatically in the data aging process if the storage has sparse file support enabled. If hole drilling is not available the complete data chunks will only be aged when not referenced anymore by the DDB. Data aging is by default performed automatically on a daily base. To initiate reclamation manually for storage without sparse file support you can perform the space reclamation process. Advice is to consult support before using this.
Quote: "To define the maximum number of allowed DDB partitions, set the Maximum allowed substore configuration parameter to 6. For more information, see Media Management Configuration: Deduplication"
In your example to use 4 nodes it would be logical to divide 4 partitions for 1 DDB over the nodes. So 1 partition per node. You can of course define 6 partitions in total and assign 2 remaining partitions on 2 nodes, but then load will not be balanced evenly over the nodes as 2 nodes will have 1 partition and 2 nodes will have 2 partitions.
Please note that load initially will not be evenly over the nodes as the existing partitions for a DDB already have references to blocks. This cannot be rebalanced to new partitions. Over time it can balance as references are aged in the DDB when the blocks referenced to are aged, but when this is achieved depends on the environment specifics.
A media agent can host multiple DDB's so in this context there would generally be a disk per partition belonging to a DDB. So if your MA is hosting 2 DDB's it can have for example 2 disks (one partition per DDB) or 4 disks (2 partitions per DDB)
I started a quick (Full) DDB Verification Job to determine how much space can be recovered with DDB Space Reclamation and I am wondering if the Total Data to Process is somewhat equivalent to Back-end size. Is it right? I'm re-reading the guide “Deduplication Building Block Guide” and planning some changes. Maybe adding more nodes. One more question regarding Back-end size (for Disk Storage). In the context of “Deduplication Building Block Guide”, Is “DDB Disk” a partition?
If yes, so a setup with “4 Node with 2 DDB Disk per node” = 4 servers with Media Agent software installed with 2 partitions each one?
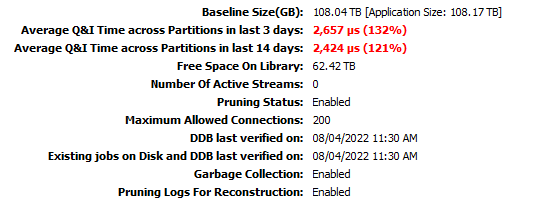
Just one more thing. Where Can I find the actual Back-end Size to consider before adding more MA nodes to Commcell? Is the Baseline Size a good starting point? Or I should take the Application Size value (Total Data to Process) above?
If you want to calculate the backend size, this is depending on multiple factors.
But I can make a basic guestimate if you provide me:
The Front End TB size for the following items:
- Files / VM Backups
- Databases
How long you want to retain backups:
- Daily
- Weekly full
- Monthly full
- Yearly full
Frequency of:
- (synthetic) full backups
How many years (1 to 5) you want to be able to use this storage space
Note: This is an indication as there are no granular specifics taken in consideration such as growth rates, additional data types (mailbox item level backup, big data agents etc), future IT projects providing additional data etc etc. A detailed calculation is needed in order to provide sizing fit to use for a storage PO.
If you want to calculate the backend size, this is depending on multiple factors.
But I can make a basic guestimate if you provide me:
The Front End TB size for the following items:
- Files / VM Backups
- Databases
How long you want to retain backups:
- Daily
- Weekly full
- Monthly full
- Yearly full
Frequency of:
- (synthetic) full backups
How many years (1 to 5) you want to be able to use this storage space
Note: This is an indication as there are no granular specifics taken in consideration such as growth rates, additional data types (mailbox item level backup, big data agents etc), future IT projects providing additional data etc etc. A detailed calculation is needed in order to provide sizing fit to use for a storage PO.
Jos,
Thank you again. I would like to dwell on the subject. Our Commvault software is already installed and I reviewing the suggested hardware specifications for MediaAgents hosting the deduplicated data to solve an Q&I issue.
I'm planning to add more nodes or disks etc.
The MA cvault-ma-02 is a physical server (HP ProLiant DL360 Gen10). Good spec.
I'm planning to use the “suggested workloads” from Hardware Specifications for Deduplication Mode (Deduplication Building Block Guide) to scale the setup. That’s why I asked you where can I find the actual Back-end Size to consider before adding more MA nodes to Commcell.
Your total backend is resulting in 500 TB (rounded up) so looking at 4 large nodes with each one partition for a specific DDB you need a 1.2TB SSD per node.
This will reduce your Q&I and facilitate in disk library size up to 600 TB.
As you currently have 190,94 TB in use so you should be able to run with this setup for the time being.
But it is advised to calculate based on near future business requirements to validate if the current sizing is still adequate.
Your total backend is resulting in 500 TB (rounded up) so looking at 4 large nodes with each one partition for a specific DDB you need a 1.2TB SSD per node.
This will reduce your Q&I and facilitate in disk library size up to 600 TB.
As you currently have 190,94 TB in use so you should be able to run with this setup for the time being.
But it is advised to calculate based on near future business requirements to validate if the current sizing is still adequate.
Is this what you are looking for?
I don't wantto make your workload any heavier, but where did you get that value? (500 TB)
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.