Hello, does anyone have any advice on this error during a VM restore test?
ERROR CODE [91:379]: Host [] was not found to restore VM [].
Source: CVMA01, Process: cvd
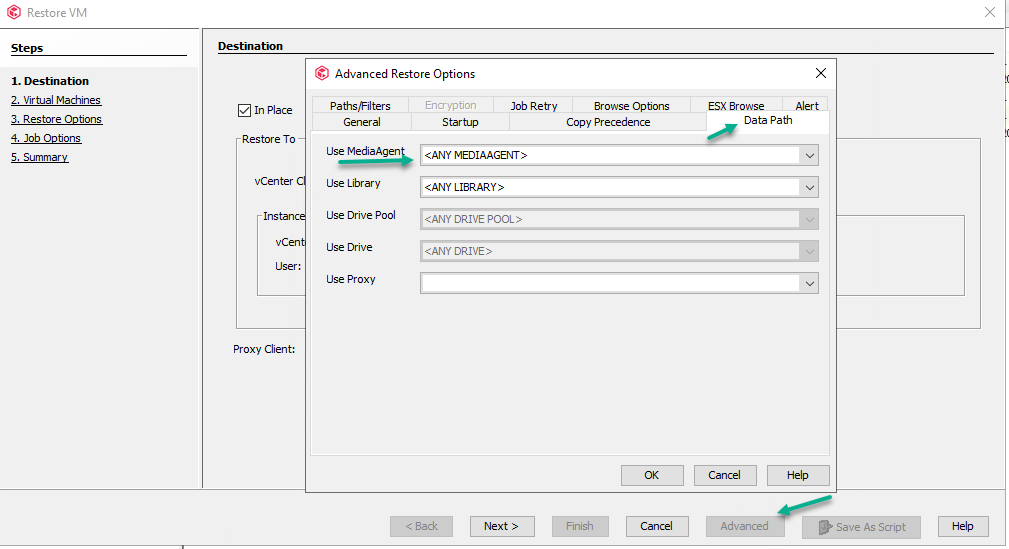
One thing I found is that Check Readiness fails when ran on the vcenter. Its pointing to a virtual (VA) server that no longer exists. Only the physical MA is present. I suspect this is the issue. Is there any way to change it to use the physical MA and not this missing VM? I do not know why the VM was removed or why the physical MA is not the server being pointed to for jobs.
The interesting thing is that the backup jobs are completing successfully like nothing is wrong. When I look at Browse and Restore, all of the servers VMDK files are marked as “Unavailable” but the other files (log, vmx, vmxf etc) on each VM have date stamps.