The reason for doing a VM level backup is to migrate the customer’s VM to a VMWARE plat-form; the customer had a file system agent and SQL agent backup however the recovery of File agent and then recovering SQL databases on top is pretty cumbersome; so doing a VM level backup should make the migration pretty easy.
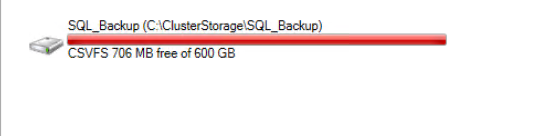
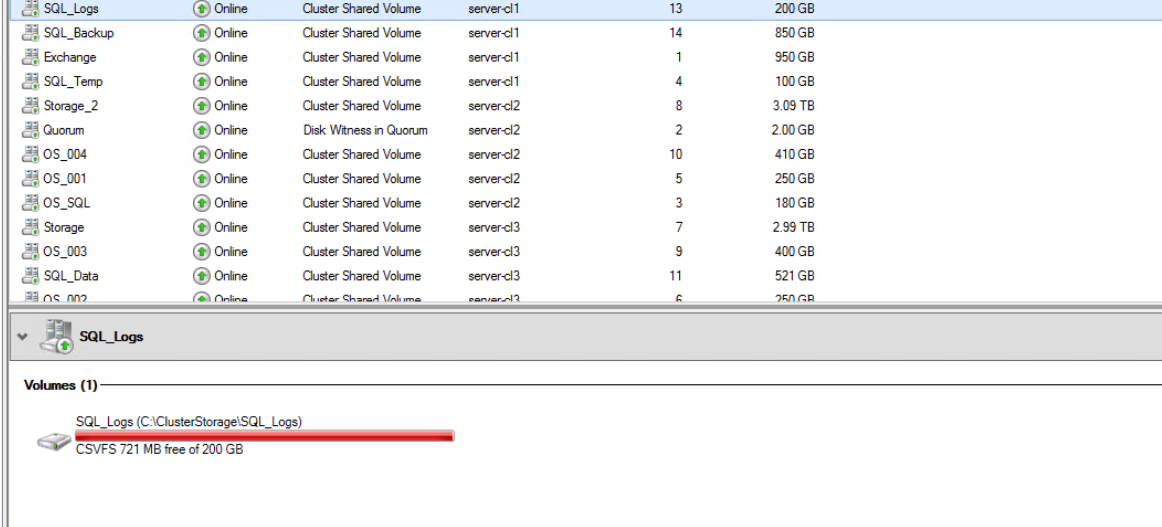
As far as VSS snapshots it concerned; thanks for the suggestion and I googled it; in hyper-v if the CSV does not have enough free space; this error will occur (found the following on the Internet); there is no way to redirect snapshots on CSV.
“
Ok I worked on the snapshot issue I had and fixed some sharable points. We're talking about: clustered hyperv, CSV, backing up VMs...
1) the child partition snapshots is taken on the physical server, not onto VM
1a) All CSVs involved by VM get the "redirect access"
2) How much free space the physical server "see" on the csv is the point. If it is 100% full (for example due to a vdh) the snapshot cannot be saved (how the VM "see" it does not matter)
3) I did not find any way to address the snapshot volume elsewhere; normal tools (vssadmin, UI, ecc) do not allow to change volume
4) of course an hardware provider (instead of the software Microsoft one) could make the job easier, but more expensive
Summary:
Leave some free space for snapshots when allocating VM's VHDs
Ciao
Paolo”