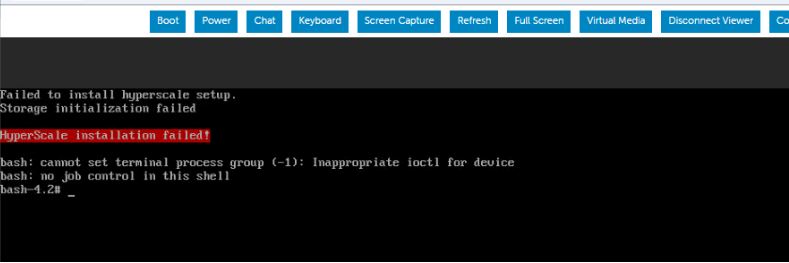
We recently received a fresh HSX 2.2212 ISO download from commvault supporth here. Whenever we try to mount the ISO and image servers after we have configured them, the installation has been failing. We have had some success install on 3 of 12 servers with the same configuration and ISO, but the remaining are always failing due to timing out or just fails immediately. We are using Idrac to mount the ISO and running the install.