


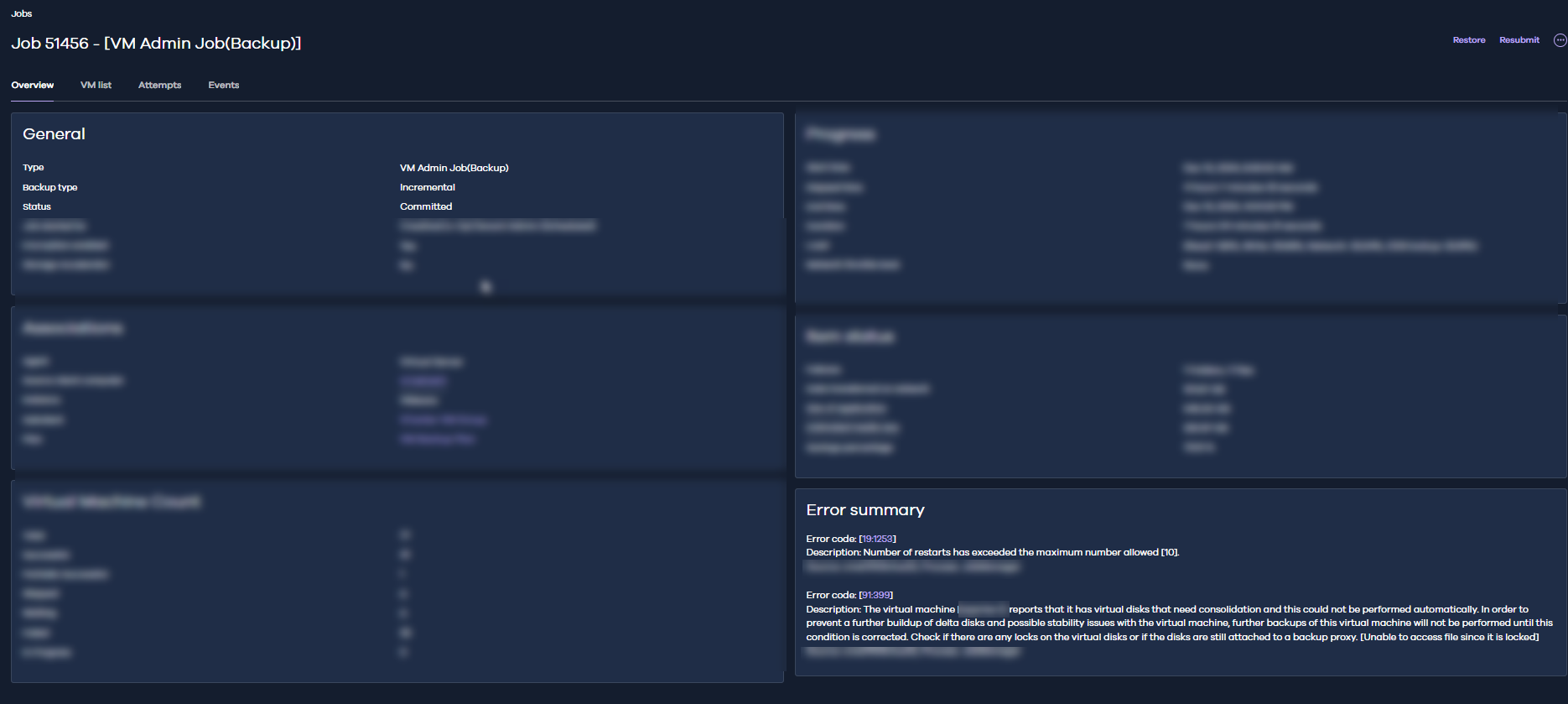
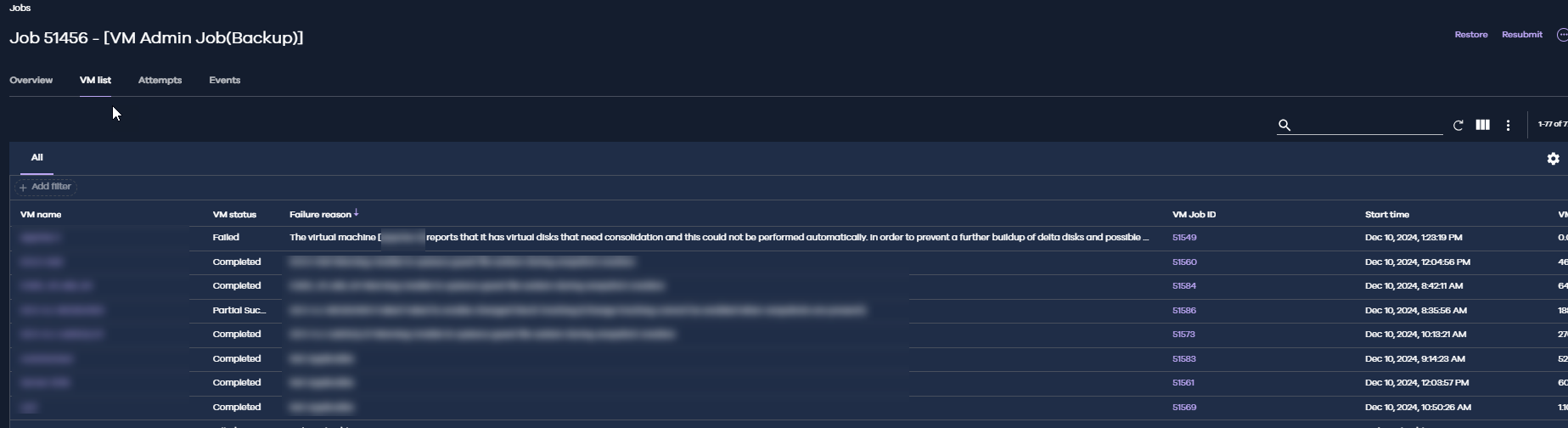
I have several VMs that are supposed to be backing up. . . but for whatever reason, the job gets killed. No error message or code (it says, “not applicable). . . No idea why they are getting killed. I’m new to BDR and CommVault, so please talk to me like I”m 5
Question
Job gets killed without explanation




Readiverse Academy Certifications

Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.