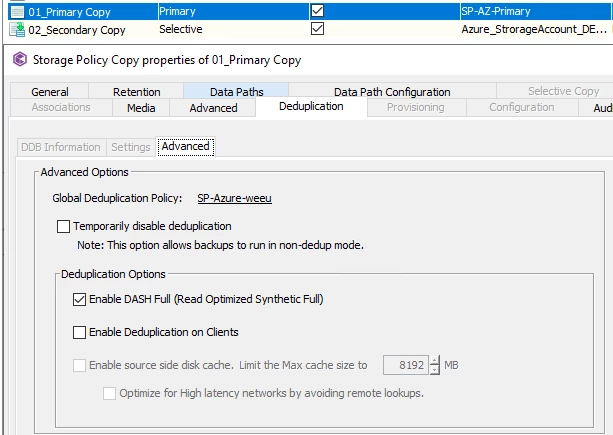
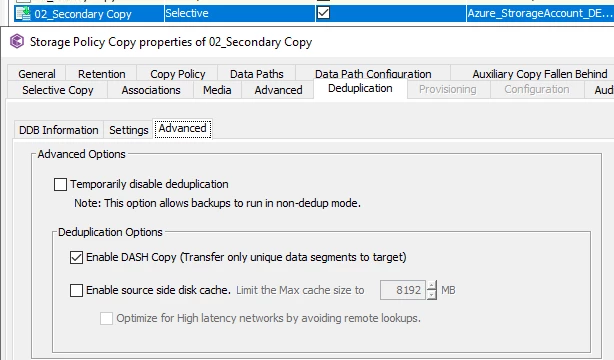
Hi,
I was wondering how people are scheduling backups. (for example file system backups)
Do you only run incrementals and Synthetic fulls? Or do you sometimes run a “real” full?
For example, 1 “real” full a month, a daily incremental and a weekly synthetic full.
I’ve always heard never to “only” use incrementals and synthetic fulls, and to slip in a “real” full backup once in a while. What would be the reasoning behind it?
Looking forward to hear your feedback.