

Hi,
Like my name state, I’m quite a beginner so please bear with me.
I’m writing this after finding a similar post answered more than a year ago that didn’t quite answer my own question.
I have this job that backup a SMB File share running on my media agent. The file share contains RDS Profiles and HomeDirectory so it contains millions of relatively small files.
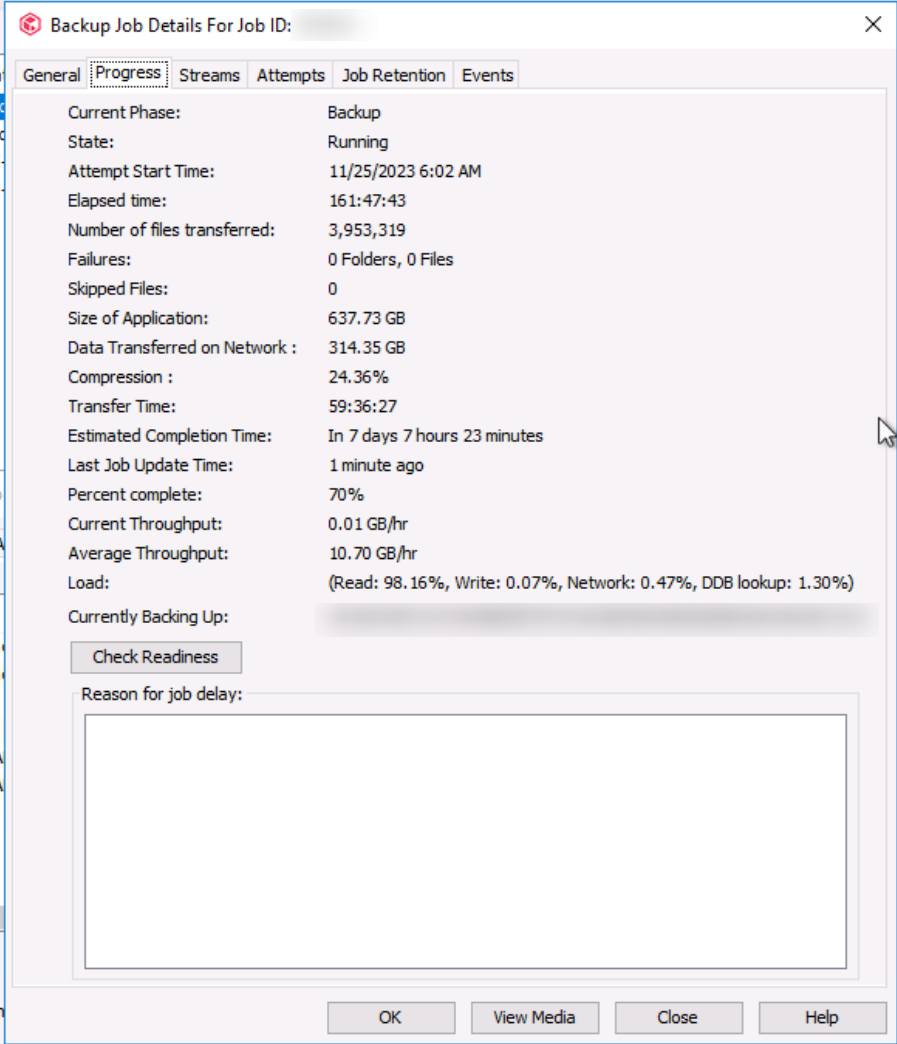
The job has been running for 3 days and it’s ETA is at least 7 days.
The Job details / Progress tab / Load portion says : Read 98% Write 0.07% Network 0.47% DDB Lookup 1.30% with a current throughput of 0.001 GB/hr. I have no idea where it got the Average Throughput from because I’ve never seen it over 1GB/hr).
The Subclient job setting / Advanced settings / Performance tab / Number of Data Readers is fixed to 10 data readers.
My questions are :
- Read being that high and others start so low, does that means the bottleneck the Read part taking too much time ?
- Does that mean I do not have enough Data Readers and augmenting the readers will speed up things or does it mean CV is already overloaded on the reading part and increasing Readers will make things worst ?
- If increasing the number of Data Readers is the solution to speed things up:
- Should I set it to Automatically use optimal number of data readers ?
- If it’s best to keep it at a fixed number, What increment would you suggest I should use next ? Skip to 100 readers and see how it goes from there ?
Thank you for all that will take time to answer my questions.
Have a good day.



