

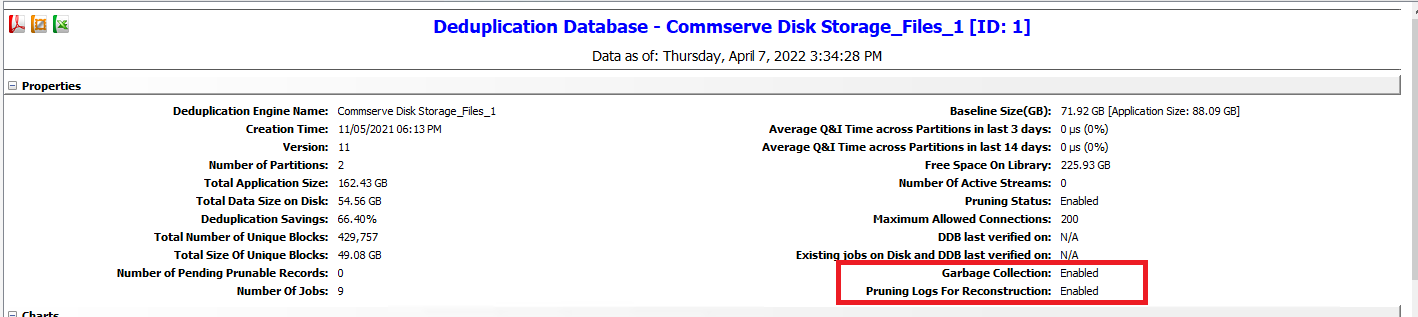
DDB lookup times spiked, SSD are old SATA and under heavy load seem to be very slow. Is pruning only related to a data that is deduplicated? If ORA or SQL DB transaction logs being written to non deduplicated storage policy is pruning at all relevant to that data? How much DDB is being used during pruning? Is it very DDB intensive process?
Solved
Pruning DDB performance issues
 +3
+3- Apprentice
Best answer by Matt Medvedeff
You can throttle the number of Pruning threads with this additional setting:
By default we run with 4 Pruner threads, if you suspect this may be too much load for the HW - try lowering to 2 or 1 and observe the performance over a few days.
If you suspect the HW performance is degraded due to age - you can run IOmeter to check the IOPS
If you have a question or comment, please create a topic



Readiverse Academy Certifications

Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.